

AnomalyDetection
AnomalyDetection[{example1,example2,…}]
与えられた例に基づいてAnomalyDetectorFunction[…]を生成する.
AnomalyDetection[LearnedDistribution[…]]
与えられた分布に基づいて異常検出器を生成する.
AnomalyDetection[True{example11,example12,…},False{example21,…}]
どの例が異常であるとみなされるべきかを示すために使うことができる.
詳細とオプション




- AnomalyDetectionは,異常(「分布ガイ」の例)を検出するために,異常がないデータの分布をモデル化しようとする.
- 例のRarerProbability値がRarerProbabilityで指定された値より下であるとき,この例は異常であるとみなされる.
- AnomalyDetectionは,数値,名義,画像等のさまざまなデータ型に使うことができる.
- 各 exampleiは,単一のデータ要素,データ要素のリスト,あるいはデータ要素の連想でよい.例はDatasetオブジェクトあるいはTabularオブジェクトとして与えることもできる.
- 異常データは以下の構文を使って指定することもできる.
-
True{e11,e12,…},False{e21,…} 異常 (True) データと異常が内データの連想 {e1,e2,…}{True,False,…} 例と異常指定の間の規則 {e1True,e2False,…} 異常指定規則のリスト {e1,e2,…}{i,j,…} 位置 i, j, …の異常 {e1,e2,…}None 異常な例はない - AnomalyDetection[examples]は,新たな例が与えられると異常を検出するAnomalyDetectorFunction[…]を与える.
- FindAnomalies[AnomalyDetectorFunction[…],data,…]を使って,与えられた検出器によって data 中の異常を求めることができる.
- 検定データが訓練データと同じ分布からのもののとき,AcceptanceThresholdは異常検出の偽陽性率に相当する.
- AnomalyDetectionは,どの例が異常であるかあるいは異常ではないかを示して使うことも指定せずに使うこともできる.どの例が異常であるか示すことは異常検出装置の訓練に役立ち,検出装置がAcceptanceThresholdの値を自動的に決定できるようにする.
- AnomalyDetection[True{example11,example12,…},False{example21,…}]のTrueは対応する例が異常であることを示し,Falseはそうではないことを示す.これらのラベルはAnomalyDetection[{example1,example2,…}{True,False,…}]およびAnomalyDetection[{example1True,example2False,…}]でも指定できる.
- AnomalyDetection[{example1,example2,…}{i,j,…}]を使って,exampleiや examplej等が異常でありその他は異常ではないとみなすべきであると指定できる.
- AnomalyDetection[{example1,example2,…}{}]は,例の中に異常なものがないと指定する.
- 次のオプションを与えることができる:
-
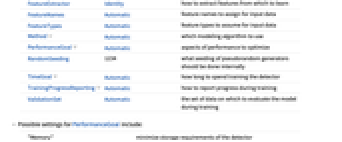
AcceptanceThreshold 0.001 例を異常であるとみなすRarerProbability閾値 FeatureExtractor Identity 学習する特徴をどのように抽出するか FeatureNames Automatic 入力データに割り当てる特徴名 FeatureTypes Automatic 入力データに仮定する特徴タイプ Method Automatic どのモデリングアルゴリズムを使用するか PerformanceGoal Automatic 最適化するパフォーマンスの局面 RandomSeeding 1234 擬似乱数生成器のどのシーディングを内部的に行うか TimeGoal Automatic 検出器の訓練にどの程度の時間を費やすか TrainingProgressReporting Automatic 訓練中の進捗状況をどのように報告するか ValidationSet Automatic 訓練中にモデルの評価に使うデータ集合 - 次は,PerformanceGoalの可能な設定である.
-
"Memory" 検出器の必要メモリを最小にする "Quality" 検出器のモデリング品質を最高にする "Speed" 新たな異常を検出するスピードを最高にする "TrainingSpeed" 検出器の生成に要する時間を最小にする Automatic スピード,品質,メモリの自動トレードオフ {goal1,goal2,…} goal1,goal2等を自動的に結合する - Methodの可能な設定はLearnDistribution[…]で与えられるものと同じである.
- 次は,TrainingProgressReportingの使用可能な設定である.
-
"Panel" 動的に更新されるグラフィカルなパネルを表示する "Print" Printを使って定期的に情報を報告する "ProgressIndicator" 単純なProgressIndicatorを表示する "SimplePanel" 動的に更新される,学習曲線なしのパネル None 情報は何も報告しない - 次は,RandomSeedingの可能な設定である.
-
Automatic 関数が呼び出されるたびに自動的にシードを再設定する Inherited 外部でシードされた乱数を使う seed 明示的な整数または文字列をシードとして使う - AnomalyDetection[…,FeatureExtractor"Minimal"]は,内部的な前処理ができるだけ簡単に行われるべきであることを示す.

例題
すべて開く すべて閉じる例 (2)
AnomalyDetectorFunctionを色のリストで訓練する:
スコープ (8)
異常な例にTrue,それ以外にFalseのラベルを付けることでAnomalyDetectorFunctionを訓練する:
異常な例はないと指定してAnomalyDetectorFunctionを訓練する:
訓練されたAnomalyDetectorFunctionを使って異常を見付ける:
AnomalyDetectorFunctionを表形式データで訓練する:
擬似実数乱数の二次元配列でAnomalyDetectorFunctionを訓練する:
訓練済みのAnomalyDetectorFunctionを使って,FindAnomaliesで新たな例の中の異常を求める:
訓練済みのAnomalyDetectorFunctionを使って異常値とそれに対応する位置を求める:
LearnedDistributionを色で訓練する:
訓練された分布に基づいてAnomalyDetectorFunctionを生成する:
オプション (5)
AcceptanceThreshold (1)
異常検出器関数を使って検定集合中の異常な例を求め,可視化する:
AcceptanceThresholdを指定して異常検出の偽陽性率を変える:
Method (1)
PerformanceGoal (1)
数値属性を使用してFisherのアヤメに関するデータ集合をロードする:
PerformanceGoalを指定して異常検出器関数を訓練する:
テキスト
Wolfram Research (2019), AnomalyDetection, Wolfram言語関数, https://reference.wolfram.com/language/ref/AnomalyDetection.html (2025年に更新).
CMS
Wolfram Language. 2019. "AnomalyDetection." Wolfram Language & System Documentation Center. Wolfram Research. Last Modified 2025. https://reference.wolfram.com/language/ref/AnomalyDetection.html.
APA
Wolfram Language. (2019). AnomalyDetection. Wolfram Language & System Documentation Center. Retrieved from https://reference.wolfram.com/language/ref/AnomalyDetection.html