AnomalyDetection
AnomalyDetection[{example1,example2,…}]
根据所给样例产生 AnomalyDetectorFunction[…].
AnomalyDetection[LearnedDistribution[…]]
基于给定分布生成异常检测器.
AnomalyDetection[True{example11,example12,…},False{example21,…}]
可用于表明应将哪些样例视为异常样例.
更多信息和选项



- AnomalyDetection 试图对非异常数据的分布进行建模,以检测异常(即“超出分布范围”的范例).
- 当范例的 RarerProbability 值低于 AcceptanceThreshold 的指定值时,该示例被视为异常示例.
- AnomalyDetection 可用于许多类型的数据,包括数值型、名称型 (nominal) 和图像型数据.
- 每个 examplei 可以是单个数据元素、数据元素列表或数据元素的关联. 也可用 Dataset 或 Tabular对象给出样例.
- 也可以使用以下语法指定异常数据:
-
True{e11,e12,…},False{e21,…} 异常 (True) 数据与非异常数据的关联 {e1,e2,…}{True,False,…} 示例与异常规格之间的规则 {e1True,e2False,…} 异常规格规则列表 {e1,e2,…}{i,j,…} 位置 i, j, … 的异常点 {e1,e2,…}None 无异常范例 - AnomalyDetection[examples] 产生 AnomalyDetectorFunction[…],它可以根据新样例检测异常点.
- FindAnomalies[AnomalyDetectorFunction[…],data,…] 可用来根据所给的检测器找出 data 中的异常点.
- 当测试数据来自与训练数据相同的分布时,AcceptanceThreshold 对应于异常检测的伪正类率 (false-positive rate).
- AnomalyDetection 可以在表明或不表明哪些样例是异常样例(哪些不是异常样例)的情况下使用. 指出哪些样例是异常样例有助于训练异常检测器,并使检测器可自动确定 AcceptanceThreshold 的值.
- 在 AnomalyDetection[True{example11,example12,…},False{example21,…}] 中,True 表明相应的样例为异常样例,False 表明不是异常样例. 也可以用 AnomalyDetection[{example1,example2,…}{True,False,…}] 和 AnomalyDetection[{example1True,example2False,…}] 来指定这些标签.
- AnomalyDetection[{example1,example2,…}{i,j,…}]可用来指定应将 examplei、examplej 等视为异常样例,其他的则视为非异常样例.
- AnomalyDetection[{example1,example2,…}None] 指定没有样例为异常样例.
- 可以给出以下选项:
-
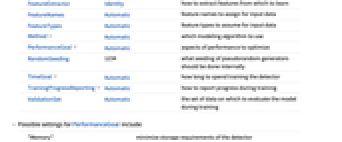
AcceptanceThreshold 0.001 将样例视为异常的 RarerProbability 阈值 FeatureExtractor Identity 怎样从要学习的样例中提取特征 FeatureNames Automatic 为输入数据分配的特征名称 FeatureTypes Automatic 假定的输入数据的特征类型 Method Automatic 使用哪种建模算法 PerformanceGoal Automatic 优化的目标 RandomSeeding 1234 应该在内部怎样对伪随机数字生成器进行播种 TimeGoal Automatic 花费多长时间来训练检测器 TrainingProgressReporting Automatic 训练过程中怎样报告进度 ValidationSet Automatic 训练过程中用来评估模型的数据集 - PerformanceGoal 的可能设置包括:
-
"Memory" 最小化检测器的存储要求 "Quality" 最大化检测器的模型质量 "Speed" 最大化检测出新异常点的速度 "TrainingSpeed" 最小化生成检测器的时间 Automatic 自动在速度、质量和内存之间权衡 {goal1,goal2,…} 自动组合 goal1、goal2 等 - Method 可能的设置与 LearnDistribution[…] 中给出的一样.
- 可使用 TrainingProgressReporting 的以下设置:
-
"Panel" 显示动态更新的图形面板 "Print" 用 Print 周期性地报告信息 "ProgressIndicator" 显示一个简单的 ProgressIndicator "SimplePanel" 动态更新的面板,不包括学习曲线 None 不报告任何信息 - RandomSeeding 可能的设置包括:
-
Automatic 每次调用方程时自动重新播种 Inherited 使用外部播种产生的随机数字 seed 明确给出整数或字符串作为种子 - AnomalyDetection[…,FeatureExtractor"Minimal"] 表示内部的预处理应该越简单越好.
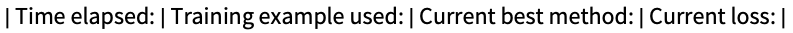
范例
打开所有单元关闭所有单元基本范例 (2)
范围 (8)
通过用 True 标注异常样例,用 False 标注其他样例来训练 AnomalyDetectorFunction:
通过指定没有样例为异常样例来训练 AnomalyDetectorFunction:
使用训练好的 AnomalyDetectorFunction 来查找异常样例:
在表格数据上训练 AnomalyDetectorFunction:
在伪随机实数组成的二维数组上训练 AnomalyDetectorFunction:
用训练过的 AnomalyDetectorFunction 和 FindAnomalies 在新样例中查找异常样例:
用训练过的 AnomalyDetectorFunction 查找异常样例及其位置:
训练 LearnedDistribution 有关颜色:
根据训练好的分布生成 AnomalyDetectorFunction:
选项 (5)
文本
Wolfram Research (2019),AnomalyDetection,Wolfram 语言函数,https://reference.wolfram.com/language/ref/AnomalyDetection.html (更新于 2025 年).
CMS
Wolfram 语言. 2019. "AnomalyDetection." Wolfram 语言与系统参考资料中心. Wolfram Research. 最新版本 2025. https://reference.wolfram.com/language/ref/AnomalyDetection.html.
APA
Wolfram 语言. (2019). AnomalyDetection. Wolfram 语言与系统参考资料中心. 追溯自 https://reference.wolfram.com/language/ref/AnomalyDetection.html 年