

TrainingProgressMeasurements
NetTrain 的一个选项,指定训练过程中要进行的测量.
更多信息
- 在 TrainingProgressMeasurements->spec 中,spec 可采用以下形式:
-
"measurement" 已命名的内置测量 NetPort["output"] 网络输出端口的值 NetPort["tdata"] 网络培训数据的值 NetPort[{lspec,"output"}] 网络内部激活函数的值 NetPort[{lspec,"weight"}] 加权数组的值 <"Measurement"spec,…> 带有子选项的测量 <"Measurement"Function[…],…> 度量的自定义函数 - 设置 TrainingProgressMeasurements{spec1,spec2,…} 将导致进行多个测量.
- 采用默认设置 TrainingProgressMeasurementsAutomatic 时,对于使用单个 CrossEntropyLossLayer 训练的网络,将自动包含 "ErrorRate" 测量.
- 对于含有 CrossEntropyLossLayer 网络,可使用以下内置测量:
-
"Accuracy" 被正确分类的实例的比例 "Accuracy"n 正确结果位于前 n 的实例的比例 "AreaUnderROCCurve" 每个类在 ROC 曲线下的面积 "CohenKappa" 科恩的卡帕系数 "ConfusionMatrix" 类别为 i 的实例被分类为类别 j 的数量 cij "ConfusionMatrixPlot" 混淆矩阵图 "Entropy" 熵,单位为 nat "ErrorRate" 没有被正确分类的实例的比例 "ErrorRate"n 错误结果位于前 n 的实例的比例 "F1Score" 每个类的 F1 分数 "FScore"β 每个类的 Fβ 分数 "FalseDiscoveryRate" 每个类的错误发现率 "FalseNegativeNumber" 假负类实例的数量 "FalseNegativeRate" 每个类的假负类率 "FalseOmissionRate" 每个类的错误遗漏率 "FalsePositiveNumber" 假正类实例的数量 "FalsePositiveRate" 每个类的假正类率 "Informedness" 每个类的 informedness "Markedness" 每个类的 markedness "MatthewsCorrelationCoefficient" 每个类的 Matthews 相关系数 "NegativePredictiveValue" 每个类的负预测值 (negative predictive value) "Perplexity" 熵的指数 "Precision" 每个类的精确度 "Recall" 每个类的召回率 "ROCCurve" 每个类的受试者工作特征 (ROC) 曲线 "ROCCurvePlot" ROC 曲线图 "ScottPi" Scott 的 pi 系数 "Specificity" 每个类的特异度 (specificity) "TrueNegativeNumber" 真负类实例的数量 "TruePositiveNumber" 真正类实例的数量 - 对于含有 MeanSquaredLossLayer 或 MeanAbsoluteLossLayer 的网络,可使用以下内置测量:
-
"FractionVarianceUnexplained" 网络无法解释的输出方差的比例 "IntersectionOverUnion" 边界框的交并比 (intersection over union) "MeanDeviation" 残差的平均绝对值 "MeanSquare" 残差的均方 "RSquared" 决定系数 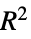
"StandardDeviation" 残差的均方根 - 自定义函数度量的纯函数将与 TrainingProgressFunction 中描述的关联一起提供.
- 可用关联 <"Measurement"measurement,opt1val1,…> 指定所给测量的子选项.
- 当测量源不明确时,可用子选项 "Source""outname" 选择网络的特定输出端口来进行测量.
- 对于按类进行计算的测量,如 "Precision"、"Recall"、"F1Score" 和 "ROCCurve",可指定子选项 "ClassAveraging"type. 可能的类型包括:
-
None 返回每个类的测量值(默认) "Macro" 返回每个类的测量值的宏平均 "Micro" 返回每个类的测量值的微平均 - 子选项 "Direction"direction 指定测量往哪个方向的变化是改进. 可能的方向值为:
-
Automatic 将 measurement 方向选为准确率提高的方向(默认) "Decreasing" measurement 应减小 "Increasing" measurement 应增大 - "Aggregation"aggregation 选项可用来对非标量 NetPort 测量值进行聚合. 可能的聚合有:
-
None 返回数组,不做任何改变(默认) "L1Norm" 返回展平数组的 L1 范数 "L2Norm" 返回展平数组的 L2 范数 "Max" 返回展平数组的最大值 "Mean" 返回展平数组的均值 "Min" 返回展平数组的最小值 "RootMeanSquare" 返回展平数组的均方根 "StandardDeviation" 返回展平数组的标准偏差 "Total" 返回展平数组的和 - "Interval"->"interval" 选项指定收集度量的间隔. 可能的区间为:
-
Automatic (默认)自动选择合适的区间 "Batch" 收集每批的度量 "Round" 收集每个回合的度量 - 如果 TrainingProgressFunction 提供给 NetTrain,所请求度量的最新值的关联可使用键 "RoundMeasurements" 和 "ValidationMeasurements" 获得.
- 通过在 NetTrain[net,data,properties] 或 NetTrainResultsObject 中指定 "RoundMeasurements" 和 "ValidationMeasurements" 作为属性,可以在训练后获得所有测量的最终值的关联.
- 用于访问特殊度量的默认键是基于度量规范:
-
"measurement" "measurement" "measurement"x "measurement" NetPort["name"] "name" NetPort[{part1,part2,…,"port"}] "part1/part2/…/port" - "Key"->"key" 选项可用于指定度量的键. 这对于唯一识别具有同样默认键的度量很有用.
- 这些测量的键还用于访问 TrainingStoppingCriterion 中轮次和验证测量的结果.
- 当通过 TrainingProgressReporting 指定文本报告形式时,可能会以汇总形式报告某些测量或根本不报告. 对于诸如 "Precision"、"Recall"、"F1Score" 等基于类的测量,报告宏平均值. 对于非标量 NetPort[…] 测量,报告标量的均值. 对于 "ROCCurve" 和 "ConfusionMatrix",则不报告任何文字汇总信息.
- "PlotType"type 子选项可用于指定如何调整度量图的
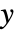 轴. 可能的类型为:
轴. 可能的类型为: -
Automatic (默认)自适应选择适当的比例 "Linear" 在线性标度中绘制度量 "Log" 在对数标度中绘制度量
范例
打开所有单元 关闭所有单元基本范例 (1)
范围 (7)
查看在 FashionMNIST 上训练的 LeNet 最终的验证精确度和召回率:
NetTrain[NetModel["LeNet"], ResourceData["FashionMNIST"], "ValidationMeasurements", ValidationSet -> Scaled[0.1], MaxTrainingRounds -> 2, TrainingProgressMeasurements -> {"Precision", "Recall"}]检查在 FashionMNIST 上训练的 LeNet 的最终验证和训练混淆矩阵(请注意,训练进度面板在默认情况下会显示训练数据的混淆矩阵;点击图在两者间切换):
NetTrain[NetModel["LeNet"], ResourceData["FashionMNIST"], {"RoundMeasurements", "ValidationMeasurements"}, ValidationSet -> Scaled[0.1], MaxTrainingRounds -> 2, TrainingProgressMeasurements -> "ConfusionMatrixPlot"]使用 "Key" 选项唯一识别度量,检查小玩具问题的最终轮次、宏观和微观平均特异性:
net = NetChain[{10, 5, SoftmaxLayer[]}];
input = RandomReal[1, {100, 10}];
output = RandomInteger[{1, 5}, {100}];
NetTrain[net, <|"Input" -> input, "Output" -> output|>, "RoundMeasurements", TrainingProgressMeasurements -> {<|"Measurement" -> "Specificity", "ClassAveraging" -> "Macro", "Key" -> "SpecMacro"|>, <|"Measurement" -> "Specificity", "ClassAveraging" -> "Micro", "Key" -> "SpecMicro"|>}]netWithFoo = NetGraph[{4, 3, 2, 1, LogisticSigmoid}, {1 -> 2 -> 3 -> 4 -> 5 , 3 -> NetPort["Foo"]}]input = RandomReal[1, {100, 4}];
output = RandomInteger[{0, 1}, {100}];
NetTrain[netWithFoo, <|"Input" -> input, "Output" -> output|>, "RoundMeasurements", RandomSeeding -> 42, TrainingProgressMeasurements -> NetPort["Foo"]]netWithoutFoo = NetGraph[{4, 3, 2, 1, LogisticSigmoid}, {1 -> 2 -> 3 -> 4 -> 5 }]NetTrain[netWithoutFoo, <|"Input" -> input, "Output" -> output|>, "RoundMeasurements", RandomSeeding -> 42, TrainingProgressMeasurements -> NetPort[{3, "Output"}]]查看 CIFAR-100 数据集的多任务训练网络的其中一个输出的错误率:
trainingData = ResourceData["CIFAR-100", "TrainingDataset"];
testData = ResourceData["CIFAR-100", "TestDataset"];
labels = Union@Normal@trainingData[All, "Label"];
sublabels = Union@Normal@trainingData[All, "SubLabel"];net = NetGraph[{100, Ramp, {20, SoftmaxLayer[]}, {100, SoftmaxLayer[]}}, {NetPort["Image"] -> 1 -> 2 -> 3 -> NetPort["Label"], 2 -> 4 -> NetPort["SubLabel"]}, "Image" -> NetEncoder[{"Image", {28, 28}}], "Label" -> NetDecoder[{"Class", labels}], "SubLabel" -> NetDecoder[{"Class", sublabels}]]NetTrain[net, trainingData, "ValidationMeasurements", ValidationSet -> testData, TrainingProgressMeasurements -> <|"Measurement" -> "ErrorRate", "Source" -> "SubLabel"|>]gen = {Function[<|"Input" -> RandomReal[1, #BatchSize], "Output" -> RandomReal[1, #BatchSize], "X" -> RandomReal[10] * #Round|>], "RoundLength" -> 64};
NetTrain[LinearLayer[{}, Input -> {}], gen, All, TrainingProgressMeasurements -> NetPort["X"]]使用自定义函数度量和 ClassifierMeasurements 度量还没有被 TrainingProgressMeasurements 支持的属性:
NetTrain[NetModel["LeNet Trained on MNIST Data", "UninitializedEvaluationNet"], "MNIST", All, TrainingProgressMeasurements -> <|"Measurement" -> Function[ClassifierMeasurements[#Net, Thread@Function[#Input -> Round[Normal@#Output - 1]]@#BatchData, "MeanDecisionUtility"]], "Interval" -> "Batch", "Key" -> "MDU"|>, MaxTrainingRounds -> 1]属性和关系 (2)
有些内置测量,如 "Precision"、"Recall"、"F1Score" 和 "AreaUnderROCCurve",对于批次没有定义,将只在每轮完成后进行测量:
res = NetTrain[NetModel["LeNet"], ResourceData["FashionMNIST"], All, MaxTrainingRounds -> 1, TrainingProgressMeasurements -> {"Accuracy", "Precision"}];
res["BatchMeasurements"]
res["RoundMeasurements"]对于非批量度量,设置 "Interval"->"Batch" 没有效果:
res = NetTrain[NetModel["LeNet"], ResourceData["FashionMNIST"], All, MaxTrainingRounds -> 1, TrainingProgressMeasurements -> <|"Measurement" -> "Precision", "Interval" -> "Batch"|>];
res["BatchMeasurements"]仅在提供验证集的情况下进行验证测量,并且将包括未在批次上定义的测量:
res["ValidationMeasurements"]NetTrain[NetModel["LeNet"], ResourceData["FashionMNIST"], "ValidationMeasurements", ValidationSet -> Scaled[0.2], MaxTrainingRounds -> 1, TrainingProgressMeasurements -> {"Accuracy", "Precision"}]"IntersectionOverUnion" 测量希望提供输入和目标边界框,且形为 {x1,y1,x2,y2} 的列表,其中 (x1,y1) 和 (x2,y2) 是描述边界框的左下角和右上角的坐标.
iou[{inputX1_, inputY1_, inputX2_, inputY2_}, {targetX1_, targetY1_, targetX2_, targetY2_}] := Block[{x1, y1, x2, y2, inputArea, targetArea, intersectionArea},
x1 = Max[inputX1, targetX1];
y1 = Max[inputY1, targetY1];
x2 = Min[inputX2, targetX2];
y2 = Min[inputY2, targetY2];
intersectionArea = Max[(x2 - x1), 0] * Max[(y2 - y1), 0];
inputArea = (inputX2 - inputX1) * (inputY2 - inputY1);targetArea = (targetX2 - targetX1) * (targetY2 - targetY1);
intersectionArea / (inputArea + targetArea - intersectionArea + $MachineEpsilon)
];data = {{{0, 0, 10, 10}, {0, 0, 10, 10}}, {{0, 0, 5, 10}, {0, 0, 10, 10}}, {{0, 0, 10, 10}, {0, 0, 5, 5}}, {{0, 0, 5, 5}, {5, 5, 10, 10}}, {{0, 0, 0, 5}, {1, 1, 1, 10}}};Map[Apply[iou]]@dataMap[NetMeasurements[MeanAbsoluteLossLayer["Input" -> 4], <|"Input" -> {First@#}, "Target" -> {Last@#}|>, "IntersectionOverUnion"]&]@data可能存在的问题 (5)
简写语法 TrainingProgressMeasurementsmeasurement 只能在 measurement 只有一个源时才能使用:
net = NetChain[{4, 3, 2, 1, LogisticSigmoid}, "Input" -> 2];
net2CELosses = NetGraph[{net, net}, {}]NetTrain[net2CELosses, "RandomData", TrainingProgressMeasurements -> "Accuracy"]NetTrain[net2CELosses, "RandomData", TrainingProgressMeasurements -> <|"Measurement" -> "Accuracy", "Source" -> "Output2"|>]如果两个或更多度量要求同样的默认键,"Key"->"key" 子选项必须用于唯一识别:
net = NetChain[{4, 3, 2, 3, SoftmaxLayer[]}, "Input" -> 2];
NetTrain[net, "RandomData", "RoundMeasurements", TrainingProgressMeasurements -> {"Accuracy", "Accuracy" -> 2}]net = NetChain[{4, 3, 2, 3, SoftmaxLayer[]}, "Input" -> 2];
NetTrain[net, "RandomData", "RoundMeasurements", TrainingProgressMeasurements -> {<|"Measurement" -> "Accuracy", "Key" -> "Acc"|>, <|"Measurement" -> "Accuracy" -> 2, "Key" -> "Top2Acc"|>}]NetTrain[NetModel["LeNet"], "MNIST", All, TrainingProgressMeasurements -> <|"Measurement" -> Function[0.5], "Interval" -> "Batch"|>]NetTrain[NetModel["LeNet"], "MNIST", TrainingProgressMeasurements -> <|"Measurement" -> Function[0.5], "Interval" -> "Batch", "Key" -> "Const"|>, TimeGoal -> 0.1]NetTrain[NetModel["LeNet"], "MNIST", All, TrainingProgressMeasurements -> <|"Measurement" -> Function[None], "Interval" -> "Batch", "Key" -> "None"|>]NetTrain[NetModel["LeNet"], "MNIST", TrainingProgressMeasurements -> <|"Measurement" -> Function[0.5], "Interval" -> "Batch", "Key" -> "Const"|>, TimeGoal -> 0.1]尝试测量用于 LossFunction 的输出端口可能会失败:
net = NetModel["LeNet Trained on MNIST Data"]res = NetTrain[net, {RandomImage[] -> 1}, All, TrainingProgressMeasurements -> NetPort["Output"], LossFunction -> "Output"]一个简单的解决方法是创建一个额外的输出端口来测量和显式标记训练数据:
net = NetGraph[{NetModel["LeNet Trained on MNIST Data"]}, {"1" -> NetPort["Output"], "1" -> NetPort["Measure"]}]res = NetTrain[net, <|"Input" -> {RandomImage[]}, "Output" -> {1}|>, All, TrainingProgressMeasurements -> NetPort["Measure"], LossFunction -> "Output"]巧妙范例 (1)
模拟在 FashionMNIST 样本上 LeNet 培训的混淆矩阵的历史:
net = NetModel["LeNet"];
data = RandomSample[ResourceData["FashionMNIST"], 1000];
res = NetTrain[net, data, "RoundMeasurementsLists", MaxTrainingRounds -> 30, TrainingProgressMeasurements -> "ConfusionMatrixPlot"];ListAnimate[res["ConfusionMatrixPlot"]]文本
Wolfram Research (2019),TrainingProgressMeasurements,Wolfram 语言函数,https://reference.wolfram.com/language/ref/TrainingProgressMeasurements.html.
CMS
Wolfram 语言. 2019. "TrainingProgressMeasurements." Wolfram 语言与系统参考资料中心. Wolfram Research. https://reference.wolfram.com/language/ref/TrainingProgressMeasurements.html.
APA
Wolfram 语言. (2019). TrainingProgressMeasurements. Wolfram 语言与系统参考资料中心. 追溯自 https://reference.wolfram.com/language/ref/TrainingProgressMeasurements.html 年