ORC (.orc)
背景
-
- Efficient, general-purpose, column-oriented data format.
- Developed by the Apache Software Foundation.
- ORC is an acronym for Optimized Row Columnar.
- Binary file format.
- Supports multiple compression methods.
Import & Export
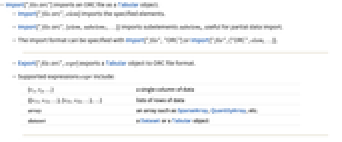
- Import["file.orc"] imports an ORC file as a Tabular object.
- Import["file.orc",elem] imports the specified elements.
- Import["file.orc",{elem,subelem1,…}] imports subelements subelemi, useful for partial data import.
- The import format can be specified with Import["file","ORC"] or Import["file",{"ORC",elem,…}].
- Export["file.orc",expr] exports a Tabular object to ORC file format.
- Supported expressions expr include:
-
{v1,v2,…} a single column of data {{v11,v12,…},{v21,v22,…},…} lists of rows of data array an array such as SparseArray, QuantityArray, etc. dataset a Dataset or a Tabular object - See the following reference pages for full general information:
-
Import, Export import from or export to a file CloudImport, CloudExport import from or export to a cloud object ImportString, ExportString import from or export to a string ImportByteArray, ExportByteArray import from or export to a byte array
Import Elements


- General Import elements:
-
"Elements" list of elements and options available in this file "Summary" summary of the file "Rules" list of rules for all available elements - Data representation elements:
-
"Data" two-dimensional array "Dataset" table data as a Dataset "Tabular" a Tabular object - Import by default uses the "Tabular" element.
- Subelements for partial data import for the "Tabular" element can take row and column specifications in the form {"Tabular",rows,cols}, where rows and cols can be any of the following:
-
n nth row or column -n counts from the end n;;m from n through m n;;m;;s from n through m with steps of s {n1,n2,…} specific rows or columns ni - Data descriptor elements:
-
"ColumnLabels" names of columns "ColumnTypes" association with data type for each column "Schema" TabularSchema object - Metadata elements:
-
"ColumnCount" number of columns stored in file "Dimensions" data dimensions "RowCount" number of rows stored in file "MetaInformation" metadata
Options

- General Import options:
-
IncludeMetaInformation All metadata types to import "Schema" Automatic schema used to construct Tabular object - General Export options:
-
"Compression" None compression method "CompressionStrategy" "Speed" compression strategy - The following settings for "Compression" are supported:
-
None no compression "LZ4" LZ4 compression "GZIP" GZIP Hadoop compression "Snappy" Snappy compression "ZSTD" ZSTD compression - The following settings for "CompressionStategy" are supported:
-
"Size" optimize size of file "Speed" optimize the speed of export
范例
打开所有单元关闭所有单元基本范例 (3)
Scope (3)
Import (3)
Show all elements available in the file:
By default, a Tabular object is returned:
Import Elements (14)
"Dataset" (2)
"Schema" (1)
Get the TabularSchema object:
"Tabular" (2)
Get the data from a file as a Tabular object:
Import Options (2)
IncludeMetaInformation (1)
By default, all metadata stored in a file is imported and embedded in the Tabular object: