Memory
Both CUDALink and OpenCLLink have a state-of-the-art memory manager that reduces the amount of memory allocation and transfer to the GPU. If used properly, the memory system can afford the application significant performance increase. The following details how to properly use the memory manager and presents some applications.
CUDALink has a memory manager that allows users to limit the number of memory copies from CPU to GPU being performed. Users have the option not to use the memory manager, but this will impact performance if memory is reused in different functions.
GPU Memory
With GPU (Graphical Processing Unit) programming, the system has two distinct memory locations. GPU (called device) memory and CPU (called host) memory. One must recognize that CUDA programs are usually bound by memory transfer, and, since available GPU memory tends to be less than CPU memory, CUDA programs must efficiently utilize GPU memory.

CUDALink provides a memory manager that allows you to efficiently utilize the GPU memory. The use of this memory manager is not required, but multiple-fold performance increase can be attained if the memory manager is used properly.
There are subcategories of CUDA memory with varying speed and limitations that are described in "CUDA Programming".
Purpose of the Memory Manager
The CUDALink memory manager allows you to efficiently copy data and reuse copied data from inside the Wolfram Language. In low-level CUDA terminology, the CUDALink memory manager allows you to control how memory is copied from the host to the ![]() device memory.
device memory.
Needs["CUDALink`"]
Needs["OpenCLLink`"]The memory manager allows you to load, allocate, unload, and get memory data.
Grid[Partition[Names["CUDA*Memory*"]~Join~Names["OpenCL*Memory*"], 2], Frame -> All]The next section describes the strategy used to perform these tasks.
Memory Manager Overview
As explained above, the purpose of the CUDALink memory manager is to minimize the amount of memory transferred from the CPU to the GPU. The following graphic shows how the memory manager behaves when memory is added, when computation using the memory is performed, and when memory is retrieved.
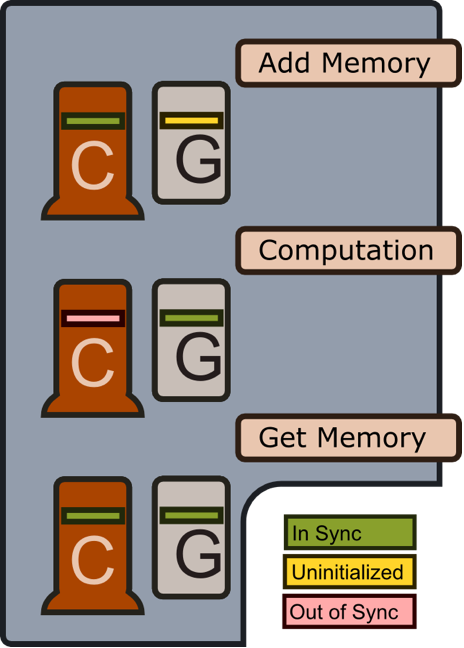
Add Memory
No GPU memory is allocated if any of the "add memory" operations are called. This lazy strategy allows a user to register more memory than the user would otherwise have available on the GPU, and only use a subset of it. It also keeps the memory allocation on the GPU to a minimum.
Computation
Before computation is performed, memory is copied from the CPU to the GPU. When computation is complete, CPU memory is marked as out of sync with the GPU memory.
Get Memory
When the "get memory" operation is called, memory is synchronized to the CPU (if it is not already synchronized).
CUDALink has the memory manager allow users to manually manage memory to increase performance. The next section describes its usage.
Usage
Recall that CUDALink manages memory automatically behind the scenes if the input is not a handle to CUDA memory.
CUDALink recognizes that, in some applications, fine control over when memory is allocated and freed gives users more flexibility and performance. On the downside, manually creating memory using CUDALink means that the user has to manually delete and manage it.
Using the memory manager is an optimization technique. As a rule of thumb, the user should get the CUDA program to work before dabbling with memory.
This section describes the syntax of the memory manager.
Loading Memory
When registering input with CUDALink, memory is not allocated on the GPU. This is part of CUDALink and OpenCLLink's strategy to limit memory allocation on the GPU device.
Only when memory is operated on does memory get allocated and copied.
First, load the CUDALink application.
Needs["CUDALink`"]This registers memory with CUDALink.
CUDAMemoryLoad[Range[10]]CUDAMemoryLoad[[image]]CUDAMemoryLoad[\!\(\*Graphics3DBox[«7»]\)]Types can be specified to define how memory is stored.
CUDAMemoryLoad[Range[10], "Byte"]The following types are supported.
| Integer | Real | Complex | |
| "Byte" | "Bit16" | "Integer32" | |
| "Byte[2]" | "Bit16[2]" | "Integer32[2]" | |
| "Byte[3]" | "Bit16[3]" | "Integer32[3]" | |
| "Byte[4]" | "Bit16[4]" | "Integer32[4]" | |
| "UnsignedByte" | "UnsignedBit16" | "UnsignedInteger" | |
| "UnsignedByte[2]" | "UnsignedBit16[2]" | "UnsignedInteger[2]" | |
| "UnsignedByte[3]" | "UnsignedBit16[3]" | "UnsignedInteger[3]" | |
| "UnsignedByte[4]" | "UnsignedBit16[4]" | "UnsignedInteger[4]" | |
| "Double" | "Float" | "Integer64" | |
| "Double[2]" | "Float[2]" | "Integer64[2]" | |
| "Double[3]" | "Float[3]" | "Integer64[3]" | |
| "Double[4]" | "Float[4]" | "Integer64[4]" |
Allocating Memory
Unlike loading memory onto the GPU, allocating memory means that memory is not initialized to any specific value. This is useful (in terms of performance) if it is known that the memory will be overwritten by some CUDALink operation.
This allocates a 10×10 matrix of integers.
CUDAMemoryAllocate[Integer, {10, 10}]Types can be passed in. In this example, you allocate a 10×10 matrix of the Float[4] vector type.
CUDAMemoryAllocate["Float[4]", {10, 10, 4}]The following types are supported.
| Integer | Real | Complex | |
| "Byte" | "Bit16" | "Integer" | |
| "Byte[2]" | "Bit16[2]" | "Integer32[2]" | |
| "Byte[3]" | "Bit16[3]" | "Integer32[3]" | |
| "Byte[4]" | "Bit16[4]" | "Integer32[4]" | |
| "UnsignedByte" | "UnsignedBit16" | "UnsignedInteger" | |
| "UnsignedByte[2]" | "UnsignedBit16[2]" | "UnsignedInteger[2]" | |
| "UnsignedByte[3]" | "UnsignedBit16[3]" | "UnsignedInteger[3]" | |
| "UnsignedByte[4]" | "UnsignedBit16[4]" | "UnsignedInteger[4]" | |
| "Double" | "Float" | "Integer64" | |
| "Double[2]" | "Float[2]" | "Integer64[2]" | |
| "Double[3]" | "Float[3]" | "Integer64[3]" | |
| "Double[4]" | "Float[4]" | "Integer64[4]" |
Getting Memory
Once memory is loaded, memory can be retrieved from the CUDALink memory manager.
CUDAMemoryGet[CUDAMemoryLoad[Range[10]]]With images, the return image has the same information as the input.
CUDAMemoryGet[CUDAMemoryLoad[[image]]]For graphics, the return value is rasterized to an image.
CUDAMemoryGet[CUDAMemoryLoad[\!\(\*Graphics3DBox[«7»]\)]]Copying Memory to CPU
This loads memory onto the GPU.
mem = CUDAMemoryLoad[{1, 2, 3}]This gets the memory information.
CUDAMemoryInformation[mem]Notice that the "DeviceStatus" is "Uninitialized" (not yet allocated) while the "HostStatus" is "Synchronized".
CUDAMemoryCopyToHost[mem]The above does not require any memory copies, since the "HostStatus" is "Synchronized".
This shows that the memory status is the same as before.
CUDAMemoryInformation[mem]In many cases this operation is not necessary, since CUDALink will do it behind the scenes. In some cases, it might be used to instruct CUDALink that the current device memory (if allocated) is what the memory should be set to.
Copying Memory to GPU
This loads memory onto the GPU.
mem = CUDAMemoryLoad[{1, 2, 3}]This gets the memory information.
CUDAMemoryInformation[mem]Notice that the "DeviceStatus" is "Uninitialized" while the "HostStatus" is "Synchronized".
CUDAMemoryCopyToDevice[mem]Since the "DeviceStatus" is "Uninitialized", this causes the GPU memory to be allocated and copied. If the "DeviceStatus" were "Initialized" or "Synchronized", then only a memory copy would be performed.
This checks the memory status.
CUDAMemoryInformation[mem]Notice that both the "DeviceStatus" and "HostStatus" are "Synchronized".
In many cases this operation is not necessary, since CUDALink will do it behind the scenes. In some cases, it might be used to instruct CUDALink that the current host memory is what the memory should be set to.
Unload Memory
This loads memory onto the GPU.
mem = CUDAMemoryLoad[{1, 2, 3}]This unloads memory from the memory manager.
CUDAMemoryUnload[mem];Performing operations on unloaded memory will give an error.
CUDAMemoryInformation[mem]Application
The memory manager can sometimes be used for convenience or for optimization. This section describes a scenario where using the memory manager makes sense.
In the following example, memory is created, copied, and destroyed each time you move the slider.
Manipulate[CUDAErosion[[image], ii], {ii, 0, 10}]A more optimized way is to load memory onto the GPU.
mem = CUDAMemoryLoad[[image]]When passing CUDAMemory to a CUDA function, memory is returned back.
Manipulate[CUDAErosion[mem, ii], {ii, 0, 10}]Use CUDAMemoryGet to get back the image.
Manipulate[CUDAMemoryGet@CUDAErosion[mem, ii], {ii, 0, 10}]Notice how the following produces different output memory when manipulated.
mem = CUDAMemoryLoad[[image]];
Manipulate[CUDAErosion[mem, ii], {ii, 0, 10}]If output memory can be overwritten, then you can load it.
outmem = CUDAMemoryLoad[[image]]The output memory is now the same.
Manipulate[CUDAErosion[mem, ii, "OutputMemory" -> outmem], {ii, 0, 10}]This is now a very efficient memory usage.
Manipulate[CUDAErosion[mem, ii, "OutputMemory" -> outmem];CUDAMemoryGet[outmem], {ii, 0, 10}]