メモリ
CUDALink と OpenCLLink の両方には,GPUへのメモリの割当てと転送を減らす最先端のメモリマネージャがある.GPU計算はメモリが制限されているため,メモリマネージャを正しく使うと,パフォーマンスが著しく改善される可能性がある.以下でメモリマネージャの正しい使い方と適用例を示す.
CUDALink にはCPUからGPUへのメモリコピー回数をユーザが制限することができるメモリマネージャがある.ユーザはメモリマネージャを使わなくてもよいが,メモリが別の関数に再利用されるとパフォーマンスに影響を与える.
GPU メモリ
GPU(グラフィカルプロセッシングユニット)プログラミングを行うときは,システムはGPU(デバイスと呼ばれる)メモリとCUP(ホストと呼ばれる)メモリの2つの別個のメモリ場所を持つ.CUDAプログラムは通常メモリ転送が制限されており,また利用できるGPUメモリはCPUメモリより少ないことが多いためにCUDAプログラムは効率的にGPUを使うようにしなければならないことを認識する必要がある.

CUDALinkにはGPUメモリを効率的に利用するためのメモリマネージャがある.このメモリマネージャは必ず使わなければいけないわけではないが,メモリマネージャを適切に使うとパフォーマンスが何倍もよくなる可能性もある.
速度と制限が変化するCUDAメモリのサブカテゴリもある.これについては「CUDAプログラミング」を参照されたい.
メモリマネージャの目的
CUDALink のメモリマネージャを使うと,効率的にデータをコピーし,コピーされたデータを効率的にWolfram言語内から再利用できるようになる.低レベルのCUDA用語では,CUDALink メモリマネージャを使うとメモリがホストから![]() デバイスメモリにどのようにコピーされるかが制御できるようになる.
デバイスメモリにどのようにコピーされるかが制御できるようになる.
メモリマネージャを使うと,メモリのデータのロード,割当て,アンロード,取得ができるようになる.
メモリマネージャ概要
前述のように,CUDALink メモリマネージャの目的はCPUからGPUへのメモリ転送量を最小化することである.下の図はメモリが加えられたときやメモリを使った計算が行われたとき,メモリが取り出されたときにメモリマネージャがどのように動作するかを示している.
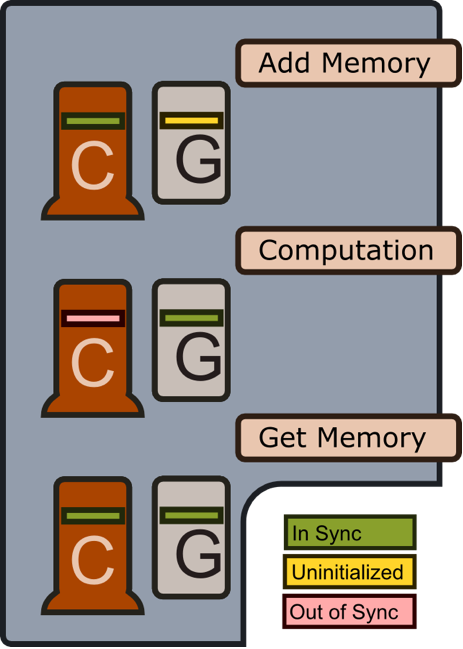
メモリの追加
「メモリの追加」操作を呼び出さないと,GPUメモリは割り当てられない.この遅延法により,ユーザはその他の方法のときに利用できるGPUメモリより多く登録でき,その一部しか使用しないことが可能になる.またGPU上のメモリ割当てを最小限にすることもできる.
計算
計算を行う前に,メモリはCPUからGPUにコピーされる.計算が完了すると,CPUメモリはGPUメモリと同期していないとしてマークされる.
メモリの取得
「メモリの取得」操作が呼び出されると,メモリは(まだ同期していない場合は)CPUと同期される.
CUDALink にはパフォーマンスを向上させるためにユーザが手動でメモリを管理することのできるメモリマネージャがある.次のセクションではその使い方を述べる.
使い方
入力がCUDAメモリへのハンドルでない場合,CUDALink は裏で自動的にメモリを管理する.
CUDALink はアプリケーションによってはメモリが割り当てられるときと解放されるときに微調整を行うと,ユーザによりよい柔軟性とパフォーマンスが提供されることを認識している一方で CUDALink を使って手動でメモリを作成するということは,ユーザは手動でそれを削除し,管理しなければならないということである.
メモリマネージャの使用は,最適化技術である.経験から言うと,ユーザはメモリのことを考えなくても,CUDAプログラムを作り上げることができる.
このセクションではメモリマネージャのシンタックスについて述べる.
メモリのロード
入力を CUDALink に登録するとき,メモリはGPU上に割り当てられない.これは CUDALink と OpenCLLink の策略の一つで,GPUデバイス上のメモリ割当てを制限するためのものである.
メモリが使われるときにのみ,メモリは割り当てられ,コピーされる.
メモリの保管のされ方を定義するために型を指定することができる.
| Integer | Real | Complex | |
| "Byte" | "Bit16" | "Integer32" | |
| "Byte[2]" | "Bit16[2]" | "Integer32[2]" | |
| "Byte[3]" | "Bit16[3]" | "Integer32[3]" | |
| "Byte[4]" | "Bit16[4]" | "Integer32[4]" | |
| "UnsignedByte" | "UnsignedBit16" | "UnsignedInteger" | |
| "UnsignedByte[2]" | "UnsignedBit16[2]" | "UnsignedInteger[2]" | |
| "UnsignedByte[3]" | "UnsignedBit16[3]" | "UnsignedInteger[3]" | |
| "UnsignedByte[4]" | "UnsignedBit16[4]" | "UnsignedInteger[4]" | |
| "Double" | "Float" | "Integer64" | |
| "Double[2]" | "Float[2]" | "Integer64[2]" | |
| "Double[3]" | "Float[3]" | "Integer64[3]" | |
| "Double[4]" | "Float[4]" | "Integer64[4]" |
メモリの割当て
GPUへのメモリのロードとは異なり,メモリの割当ては特定の値に初期化されないということを意味する.これはメモリが CUDALink の演算のどこかで上書きされることが分かっているときは(パフォーマンスの観点から)便利である.
型が渡される.この例ではFloat[4]ベクトル型の0×10の行列を割り当てる.
| Integer | Real | Complex | |
| "Byte" | "Bit16" | "Integer" | |
| "Byte[2]" | "Bit16[2]" | "Integer32[2]" | |
| "Byte[3]" | "Bit16[3]" | "Integer32[3]" | |
| "Byte[4]" | "Bit16[4]" | "Integer32[4]" | |
| "UnsignedByte" | "UnsignedBit16" | "UnsignedInteger" | |
| "UnsignedByte[2]" | "UnsignedBit16[2]" | "UnsignedInteger[2]" | |
| "UnsignedByte[3]" | "UnsignedBit16[3]" | "UnsignedInteger[3]" | |
| "UnsignedByte[4]" | "UnsignedBit16[4]" | "UnsignedInteger[4]" | |
| "Double" | "Float" | "Integer64" | |
| "Double[2]" | "Float[2]" | "Integer64[2]" | |
| "Double[3]" | "Float[3]" | "Integer64[3]" | |
| "Double[4]" | "Float[4]" | "Integer64[4]" |
メモリの取得
メモリがロードされたら,メモリは CUDALink メモリマネージャから取り出すことができる.
グラフィックスについては,戻り値はラスタライズされた画像である.
CPUへのメモリのコピー
"HostStatus"は"Synchronized"であるが,"DeviceStatus"は"Uninitialized"(まだ割り当てられていない)ことに注目されたい.
"HostStatus"が"Synchronized"なので,上記にはメモリのコピーは必要ない.
多くの場合この操作は CUDALink が裏で行うので不要である.場合によってはメモリが現在のデバイスメモリ(割り当てられている場合は)に設定されるべきであることを CUDALink に示すためにこれが使われる.
GPUへのメモリのコピー
"HostStatus"は"Synchronized"であるが,"DeviceStatus"は"Uninitialized"であることに注目されたい.
"DeviceStatus"は"Uninitialized"であるので,この場合はGPUメモリは割り当てられ,コピーされる."DeviceStatus"が"Initialized"または"Synchronized"の場合は,メモリコピーのみが行われる.
"DeviceStatus"も"HostStatus"も"Synchronized"である.
多くの場合この操作は CUDALink が裏で行うので不要である.場合によってはメモリが現在のホストメモリに設定されるべきであることを CUDALink に示すためにこれが使われる.
メモリのアンロード
アンロードされたメモリに対して操作を行うとエラーが返される.
適用例
メモリマネージャーは便利さのために,または最適化のために使われることがある.このセクションではメモリマネージャを使うとよい場合の例を挙げる.
次の例では,スライダーを動かすたびにメモリは作成され,コピーされ,破壊される.
メモリをGPUにロードするというのは,より最適化された方法である.
CUDAMemoryをCUDA関数に渡すとき,メモリは戻される.
CUDAMemoryGetを使って画像を取り戻す.
以下で操作を行うと,生成される出力メモリがいかに異なるかに注目されたい.
出力メモリが上書きできるなら,それをロードすることができる.