AudioGenerator


AudioGenerator
AudioGenerator[model]
生成 1 秒给定模型 model 的音频.
AudioGenerator[model,t]
生成 t 秒音频.
AudioGenerator[model,t,"type"]
生成指定类型 "type" 的音频样本.
更多信息和选项

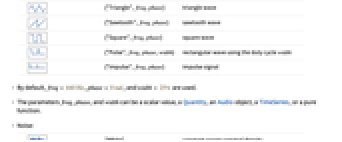

- AudioGenerator 可以生成不同类型的音频,包括振荡和噪音.
- model 的可能设置包括:
-
f 对随机时间函数 f 抽样(以秒计量) proc 从随机过程 proc 中生成样本 tseries 从 TimeSeries tseries 中生成样本 "model" 根据已命名函数 "model" 生成样本 - 无声:
-

"Silence" 无声(零)信号 - 振荡:
-
{"Sin",freq,phase} 正弦波 
{"Triangle",freq,phase} 三角波 
{"Sawtooth",freq,phase} 锯齿波 
{"Square",freq,phase} 方形波 
{"Pulse",freq,phase,width} 使用占空因数 width 的长方形波 
{"Impulse",freq,phase} 脉冲信号 - 默认情况下,使用
![freq=TemplateBox[{440, "Hz", hertz, "Hertz"}, Quantity]](Files/AudioGenerator.zh/8.png "freq=TemplateBox[{440, \"Hz\", hertz, \"Hertz\"}, Quantity]") 、
、![phase=TemplateBox[{0, "rad", radians, "Radians"}, Quantity]](Files/AudioGenerator.zh/9.png "phase=TemplateBox[{0, \"rad\", radians, \"Radians\"}, Quantity]") 和
和 ![width=TemplateBox[{25, "%", percent, "Percent"}, QuantityPostfix]](Files/AudioGenerator.zh/10.png "width=TemplateBox[{25, \"%\", percent, \"Percent\"}, QuantityPostfix]") .
. - 参数 freq、phase 和 width 可为标量、数量 Quantity、Audio 对象、TimeSeries、或纯函数.
- 噪音:
-

"White" 恒定功率谱密度 
"Pink" 服从  的功率谱密度
的功率谱密度
"Brown" 服从 
"Blue" 服从 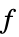 的功率谱密度
的功率谱密度
{"Color",α} 服从 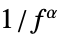 且
且 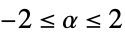 的功率谱密度
的功率谱密度
{"White",dist} 从 dist 抽样的随机噪音数值 
"PeriodicRandomNoise" 拥有恒定振幅和随机相位的正弦组成总和 - 其他:
- AudioGenerator 生成类型为 "Real32" 的音频对象. "type" 的可能设置类型参见 Audio 的页面.
- AudioGenerated 与 Audio 的选项相同.
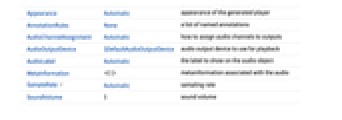
所有选项的列表
范例
打开所有单元 关闭所有单元范围 (17)
基本用法 (2)
模型说明 (15)
振荡 (5)
使用另一个 Audio 对象控制正弦波的频率:
使用 TimeSeries 控制正弦波的频率:
噪音生成器 (5)
使用函数 (1)
AudioGenerator 支持时间函数:
使用 TimeSeries (2)
选项 (1)
SampleRate (1)
默认情况下,使用 SampleRate->44100:
应用 (8)
根据时间数据生成音频 (2)
生成多频率 (3)
可能存在的问题 (2)


互动范例 (3)
巧妙范例 (4)
使用基为 24 的 Pi 的小数位生成正弦振荡器的频率系列:
使用 DiscreteMarkovProcess 创建旋律:
Wolfram Research (2016),AudioGenerator,Wolfram 语言函数,https://reference.wolfram.com/language/ref/AudioGenerator.html.
文本
Wolfram Research (2016),AudioGenerator,Wolfram 语言函数,https://reference.wolfram.com/language/ref/AudioGenerator.html.
CMS
Wolfram 语言. 2016. "AudioGenerator." Wolfram 语言与系统参考资料中心. Wolfram Research. https://reference.wolfram.com/language/ref/AudioGenerator.html.
APA
Wolfram 语言. (2016). AudioGenerator. Wolfram 语言与系统参考资料中心. 追溯自 https://reference.wolfram.com/language/ref/AudioGenerator.html 年