

CreateSemanticSearchIndex
CreateSemanticSearchIndex[source]
creates a search index from the data in source.
CreateSemanticSearchIndex[{source1,…}]
creates a search index with a collection of sources sourcei.
CreateSemanticSearchIndex[{source1val1,…}]
associates the source sourcei to the value vali.
CreateSemanticSearchIndex[data,"name"]
gives the search index the specified name.
Details and Options
- CreateSemanticSearchIndex is used to extract features from text that can be used to search the content semantically.
- Possible values for source are:
-
"string" a plain string File["path"] individual file URL["url"] the text representation of "url" CloudObject[…] a cloud object LocalObject[…] a local object ContentObject[…] a content object {source1,source2,…} list of sources - Sources can be annotated. Every chunk from a given source will have the same annotation.
- Possible ways to specify annotations include:
-
{source1val1,…} a list of sources and associated values {source1,…}{val1,…} a rule between sources and values - Accepted forms of vali include:
-
"string" string labels <"tag1"v1,…> an association of tags and metadata values - CreateSemanticSearchIndex supports the following options:
-
DistanceFunction EuclideanDistance the distance function to use FeatureExtractor "MiniLM" how to extract features from text chunks GeneratedAssetLocation $GeneratedAssetLocation the location of the index Method Automatic method details OverwriteTarget Automatic whether to overwrite an existing location ProgressReporting $ProgressReporting whether to report the progress of the computation WorkingPrecision "Real32" precision of floating-point calculations - Possible values for DistanceFunction include EuclideanDistance, SquaredEuclideanDistance, CosineDistance, JaccardDissimilarity and HammingDistance.
- Possible values for FeatureExtractor include:
-
"MiniLM" a local model based on SentenceBERT LLMConfiguration an LLM-based sentence embedding f a custom extractor function - Custom extractors f must operate on a list of strings and produce a list of vectors of the same length.
- Detailed options can be given using Method<opt1val1>. Possible values for opti are:
-
"ContextPadding" 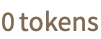
minimal overlap between chunks "MaximumItemLength" 
maximum length of a text chunk "MinimumItemLength" 
minimum length of a text chunk "SplitPattern" Automatic where to split long strings - The automatic "SplitPattern" tries to split a source text in paragraphs, newlines and words to create chunks between "MinimumItemLength" and "MaximumItemLength".
- Possible settings for WorkingPrecision include:
-
"Integer8" signed 8-bit integers from -128 through 127 "Real32" single-precision real (32-bit) "Real64" double-precision real (64-bit)
Examples
open all close allBasic Examples (2)
Create a new SemanticSearchIndex:
index = CreateSemanticSearchIndex[ResourceData["Alice in Wonderland"], "Alice"]Search in the text by semantic similarity:
Short /@ SemanticSearch[index, "talking insect", MaxItems -> 4]Create an index with multiple labeled sources:
index = CreateSemanticSearchIndex[{ResourceData["Alice in Wonderland"] -> "Alice", ResourceData["Death in Venice"] -> "Venice"}]Recover the label for the most similar items:
SemanticSearch[index, "insects"]Scope (6)
Data Sources (4)
Create an index from a string:
CreateSemanticSearchIndex["Cats, with their mysterious charm and playful antics, effortlessly capture our hearts, prancing gracefully through sunbeams, curling up in cozy spots, and purring softly, reminding us of the joy they bring."]CreateSemanticSearchIndex[File["ExampleData/USConstitution.txt"]]CreateSemanticSearchIndex[URL["http://www.wolfram.com"]]Create an index with a specific name:
CreateSemanticSearchIndex[ResourceData["Alice in Wonderland"], "Alice"]Annotations (2)
Annotate sources with a label:
index = CreateSemanticSearchIndex[{ResourceData["Friends, Romans, Countrymen"] -> "Caesar", ResourceData["JFK Inaugural Address"] -> "JFK"}]Each chunk inherits the correspondent source label:
index["Label"]The label is returned when performing search:
SemanticSearch[index, "honour"]Annotated sources with tagged metadata:
CreateSemanticSearchIndex[{ResourceData["Alice in Wonderland"] -> <|"Author" -> "Lewis Carroll", "Date" -> 1865 |>, ResourceData["Friends, Romans, Countrymen"] -> <|"Author" -> "William Shakespeare", "Date" -> 1609|>}]Specify the annotations in a separate Association:
CreateSemanticSearchIndex[{ResourceData["Alice in Wonderland"], ResourceData["Friends, Romans, Countrymen"]} -> {<|"Author" -> "Lewis Carroll", "Date" -> 1865|>, <|"Author" -> "William Shakespeare", "Date" -> 1609|>}]Options (11)
DistanceFunction (1)
Specify a custom distance function for the index:
CreateSemanticSearchIndex[{"beautiful", "mysterious", "vibrant", "ancient"}, DistanceFunction -> CosineDistance]By default, EuclideanDistance is used:
CreateSemanticSearchIndex[{"beautiful", "mysterious", "vibrant", "ancient"}]["Database"]["DistanceFunction"]FeatureExtractor (2)
Train a custom feature extractor:
fe = FeatureExtraction[TextWords@ResourceData["Declaration of Independence"]]Use it to extract features from another text:
CreateSemanticSearchIndex[ResourceData["A Far Country"], FeatureExtractor -> fe]Use an LLM-based feature extractor:
CreateSemanticSearchIndex[{"hi there"}, FeatureExtractor -> LLMConfiguration["Model" -> {"OpenAI", "text-embedding-3-small"}]]GeneratedAssetLocation (3)
Specify a custom location to store the index:
index = CreateSemanticSearchIndex[ResourceData["Declaration of Independence"], GeneratedAssetLocation -> "CloudObject"]index["Location"]By default, the index is stored in a local object:
CreateSemanticSearchIndex[RandomWord[10]]["Location"]Store the vector index in a file:
file = File[FileNameJoin[{$TemporaryDirectory, "testfile"}]]CreateSemanticSearchIndex[RandomWord[10], GeneratedAssetLocation -> file]%["Location"]Recreate the database from the file reference:
SemanticSearchIndex[File["/private/var/folders/05/v_ct9frn7zv4vy6f2q18y2r80000gn/T/testfile"]]Method (2)
Create a text with multiple very short entries:
text = "abacus: a calculator that performs arithmetic functions by manually sliding counters on rods or in groovesa tablet placed horizontally on top of the capital of a column as an aid in supporting the architrave
abaft: at or near or toward the stern of a ship or tail of an airplanepreposition
abalone: any of various large edible marine gastropods of the genus Haliotis having an ear-shaped shell with pearly interior
abandoned: forsaken by owner or inhabitants free from constraint";The entire text will be embedded as a single chunk:
CreateSemanticSearchIndex[text]Adjusting the minimum and maximum item length to chunk into more relevant sections:
CreateSemanticSearchIndex[text, Method -> {"MinimumItemLength" -> 1, "MaximumItemLength" -> 64}]Create several paragraphs of text:
definitions = Map[StringJoin[#, ": ", WordDefinition[#]]&, RandomWord[50]];
Short[definitions]Join them with nonstandard separators:
text = StringRiffle[definitions, " !!! "];The default automatic paragraph and sentence chunking will give poor results:
First@CreateSemanticSearchIndex[text]["Items"]Use a custom split pattern to create chunks at the custom dividers:
First@CreateSemanticSearchIndex[text, Method -> <|"SplitPattern" -> StringExpression["!!!"], "MinimumItemLength" -> 4|>]["Items"]OverwriteTarget (2)
The index's automatic location is determined by its name:
CreateSemanticSearchIndex[StringRiffle[RandomWord[10]], "myDB"]With default OverwriteTargetAutomatic, a new index name is generated to avoid collisions:
CreateSemanticSearchIndex[StringRiffle[RandomWord[10]], "myDB"]To force overwriting, use OverwriteTargetTrue:
CreateSemanticSearchIndex[StringRiffle[RandomWord[10]], "myDB", OverwriteTarget -> True]Use OverwriteTargetFalse to perform a strict check:
CreateSemanticSearchIndex[RandomWord[10], "myDB", OverwriteTarget -> False]OverwriteTargetFalse will also prevent reusing the same index name in a different location:
CreateSemanticSearchIndex[RandomWord[10], "myDB", GeneratedAssetLocation -> File["myDBfile"], OverwriteTarget -> False]CreateFile@File["myIndexfile"]By default, existing files are not overwritten:
CreateSemanticSearchIndex[RandomWord[10], GeneratedAssetLocation -> File["myIndexfile"]]Use OverwriteTargetTrue to overwrite the existing file:
CreateSemanticSearchIndex[RandomWord[10], GeneratedAssetLocation -> File["myIndexfile"], OverwriteTarget -> True]WorkingPrecision (1)
Specify a custom working precision for the embedding vectors:
index = CreateSemanticSearchIndex[ResourceData["Shakespeare's Sonnets"], WorkingPrecision -> "Integer8"]The working precision is stored in the index's vector database:
index["Database"]index["Database"]["WorkingPrecision"]Applications (2)
Create a reverse mapping between a word and its definitions:
data = Map[StringRiffle[WordDefinition[#]] -> #&, WordList[]];CreateSemanticSearchIndex[data, "definitions"]Perform reverse lookup in a dictionary by matching the query against the definitions:
SemanticSearch["definitions", "small land insect"]index = CreateSemanticSearchIndex[ResourceData["Shakespeare's Sonnets"]]Search for the quote without knowing its exact wording:
SemanticSearch[index, "a day in the summer", MaxItems -> 1]Properties & Relations (1)
Create an index and retrieve the embeddings:
text = "This is a sentence."
semanticEmbeddings = Normal@CreateSemanticSearchIndex[text]["Embeddings"];
Short[semanticEmbeddings]FeatureExtract can use the specified "SentenceVector" extractor to create similar embeddings:
featureEmbeddings = FeatureExtract[{text}, "SentenceVector"];
Short@featureEmbeddingsPossible Issues (2)
An input string is always interpreted as text:
CreateSemanticSearchIndex["https://www.wolfram.com"]["Items"]To follow the link, use the URL wrapper:
CreateSemanticSearchIndex[URL["https://www.wolfram.com"]]["Items"]//First//ShortUse File to import file content:
FileCreateSemanticSearchIndex[File["ExampleData/USConstitution.txt"]]["Items"]//First//ShortText with multiple small entries:
text = "abacus: a calculator that performs arithmetic functions by manually sliding counters on rods or in groovesa tablet placed horizontally on top of the capital of a column as an aid in supporting the architrave
abaft: at or near or toward the stern of a ship or tail of an airplanepreposition
abalone: any of various large edible marine gastropods of the genus Haliotis having an ear-shaped shell with pearly interior
abandoned: forsaken by owner or inhabitants free from constraint";Chunking will not occur, as the length of the string is less than the default maximum:
index = CreateSemanticSearchIndex[text, Method -> {"MinimumItemLength" -> 1}]Lower the maximum item length to ensure chunking takes place:
index = CreateSemanticSearchIndex[text, Method -> {"MinimumItemLength" -> 1, "MaximumItemLength" -> 64}]Text
Wolfram Research (2024), CreateSemanticSearchIndex, Wolfram Language function, https://reference.wolfram.com/language/ref/CreateSemanticSearchIndex.html (updated 2025).
CMS
Wolfram Language. 2024. "CreateSemanticSearchIndex." Wolfram Language & System Documentation Center. Wolfram Research. Last Modified 2025. https://reference.wolfram.com/language/ref/CreateSemanticSearchIndex.html.
APA
Wolfram Language. (2024). CreateSemanticSearchIndex. Wolfram Language & System Documentation Center. Retrieved from https://reference.wolfram.com/language/ref/CreateSemanticSearchIndex.html