ArrowDataset
ArrowDataset
Background & Context
-
- Efficient multi-file, column-oriented data format.
- Developed by the Apache Software Foundation.
Import & Export
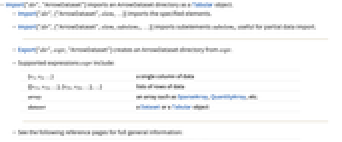
- Import["dir","ArrowDataset"] imports an ArrowDataset directory as a Tabular object.
- Import["dir",{"ArrowDataset",elem,…}] imports the specified elements.
- Import["dir",{"ArrowDataset",elem,subelem1,…}] imports subelements subelemi, useful for partial data import.
- Export["dir",expr,"ArrowDataset"] creates an ArrowDataset directory from expr.
- Supported expressions expr include:
-
{v1,v2,…} a single column of data {{v11,v12,…},{v21,v22,…},…} lists of rows of data array an array such as SparseArray, QuantityArray, etc. dataset a Dataset or a Tabular object - See the following reference pages for full general information:
-
Import, Export import from or export to a file CloudImport, CloudExport import from or export to a cloud object ImportString, ExportString import from or export to a string ImportByteArray, ExportByteArray import from or export to a byte array
Import Elements

- General Import elements:
-
"Elements" list of elements and options available in this file "Summary" summary of the file "Rules" list of rules for all available elements - Data representation elements:
-
"Data" two-dimensional array "Dataset" table data as a Dataset "Tabular" a Tabular object - Additional elements can be specified depending on the "Format" option. See "Parquet", "ArrowIPC", "ORC", "CSV", or "TSV" for detailed element descriptions.
- Import by default uses the "Tabular" element.
- Subelements for partial data import for the "Tabular" element can take row and column specifications in the form {"Tabular",rows,cols}, where rows and cols can be any of the following:
-
n nth row or column -n counts from the end n;;m from n through m n;;m;;s from n through m with steps of s {n1,n2,…} specific rows or columns ni - Data descriptor elements:
-
"ColumnLabels" names of columns "ColumnTypes" association with data type for each column "Schema" TabularSchema object
Options

- General Import options:
-
"Format" Automatic underlying format to use "Partitioning" None partitioning scheme - General Export options:
-
"Format" "Parquet" underlying format to use "MaxPartitions" 4096 maximal number of partitions "MaxRowsPerFile" Infinity maximal number of rows per file "NameTemplate" "part{i}" file name template "Partitioning" "Hive" partitioning scheme "SplitColumns" Automatic columns used for partitioning - Import supports the following settings for "Partitioning":
-
None no partitioning "Hive" Hive partitioning {col1,col2,…} directory partitioning with partition keys {"Directory", {col1,col2,…}} directory partitioning with partition keys - Export supports the following settings for "Partitioning":
-
"Directory" directory partitioning "Hive" Hive partitioning - Additional options can be specified depending on the "Format" option. See "Parquet", "ArrowIPC", "ORC", "CSV", or "TSV" for detailed options descriptions.
Examples
open all close allScope (3)
Import (3)
Show all elements available in the file:
By default, a Tabular object is returned:
Import Elements (14)
"Dataset" (2)
"Schema" (1)
Get the TabularSchema object:
"Tabular" (2)
Get the data from a file as a Tabular object:
Import Options (2)
"Format" (1)
"Partitioning" (1)
By default, "Partitioning"None is used. Notice that the column used for partitioning is not imported:
Use "Partitioning" option with correct setting to get all columns:
Export Options (6)
Possible Issues (1)
Export requires "SplitColumns" option: