ArrowDataset
ArrowDataset
背景
-
- 高效的多文件、列式数据格式.
- 由 Apache 软件基金会开发.
导入与导出
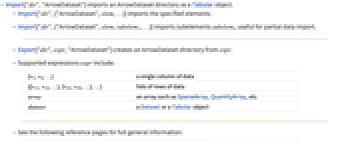
- Import["dir","ArrowDataset"] 将 ArrowDataset 目录导入为 Tabular 对象.
- Import["dir",{"ArrowDataset",elem,…}] 导入指定的元素.
- Import["dir",{"ArrowDataset",elem,subelem1,…}] 导入子元素 subelemi,适用于部分数据导入.
- Export["dir",expr,"ArrowDataset"] 从 expr 创建一个 ArrowDataset 目录.
- 支持的表达式 expr 包括:
-
{v1,v2,…} 单列数据 {{v11,v12,…},{v21,v22,…},…} 数据行列表 array 数组,例如 SparseArray、QuantityArray 等 dataset Dataset 或 Tabular 对象 - 有关完整的通用信息,请参阅以下参考页面:
-
Import, Export 从文件导入或导出至文件 CloudImport, CloudExport 从云对象导入或导出至云对象 ImportString, ExportString 从字符串导入或导出为字符串 ImportByteArray, ExportByteArray 从字节数组导入或导出为字节数组
导入元素

- Import 的通用参数:
-
"Elements" 此文件中可用的元素和选项列表 "Summary" 文件摘要 "Rules" 所有可用元素的规则列表 - 数据表示元素:
-
"Data" 二维数组 "Dataset" 作为 Dataset 的表格数据 "Tabular" Tabular 对象 - 其他元素可以根据 "Format" 选项指定. 有关元素的详细描述,请参阅 "Parquet"、"ArrowIPC"、"ORC"、"CSV" 或 "TSV".
- Import 默认使用 "Tabular" 元素.
- "Tabular" 元素的部分数据导入的子元素可以采用 {"Tabular",rows,cols} 形式的行和列规范,其中 rows 和 cols 可以是以下任一种:
-
n 第 n 行或列 -n 从最后开始计数 n;;m 从 n 到 m n;;m;;s 从 n 到 m,步长为 s {n1,n2,…} 特定行或列 ni - 数据描述符元素:
-
"ColumnLabels" 列名 "ColumnTypes" 与每列数据类型的关联 "Schema" TabularSchema 对象
选项

- Import 的通用选项:
-
"Format" Automatic 要使用的底层格式 "Partitioning" None 分区方案 - Export 的通用选项:
-
"Format" "Parquet" 要使用的底层格式 "MaxPartitions" 4096 分区的最大数量 "MaxRowsPerFile" Infinity 每个文件的最大行数 "NameTemplate" "part{i}" 文件名模板 "Partitioning" "Hive" 分区方案 "SplitColumns" Automatic 用于分区的列 - Import 支持以下 "Partitioning" 设置:
-
None 无分区 "Hive" Hive 分区 {col1,col2,…} 使用分区键进行目录分区 {"Directory", {col1,col2,…}} 使用分区键进行目录分区 - Export 支持以下 "Partitioning" 设置:
-
"Directory" 目录分区 "Hive" Hive 分区 - 其他选项可以根据 "Format" 选项指定. 有关选项的详细描述,请参阅。有关详细选项描述,请参阅 "Parquet"、"ArrowIPC"、"ORC"、"CSV" 或 "TSV".
范例
打开所有单元 关闭所有单元范围 (3)
导入 (3)
导入元素 (14)
导入选项 (2)
"Partitioning" (1)
默认情况下,使用 "Partitioning"None. 注意,用于分区的列未被导入:
导出选项 (6)
"MaxPartitions" (1)
"Partitioning" (1)
默认情况下,Export 使用 "Hive" 分区:
可能存在的问题 (1)
Export 需要 "SplitColumns" 选项: