"AudioSTFT" (神经网络编码器)
NetEncoder["AudioSTFT"]
表示一个编码器,将音频文件或对象转换成它的短时傅立叶变换.
NetEncoder[{"AudioSTFT","param"->val,…}]
表示一个编码器,具有用于预处理的特定参数.
更多信息



- "AudioSTFT" 编码器对信号进行分区,将每个分区与窗口函数相乘,并计算每个分区的傅里叶变换. 傅里叶变换的结果是复数,并且对于它们中的每一个,编码器返回实部和虚部的列表. 原始信号可以从 STFT 重建,因为没有信息丢失.
- NetEncoder[…][input] 对一个输入应用编码器,产生一个 "Real32"输出.
- NetEncoder[…][{input1,input2,…}] 对一系列输入应用编码器,产生一系列输出.
- 当给定一个 NumericArray 作为输入时,输出将会是一个 NumericArray.
- 编码器的输入可以为 Audio 对象或 File[…] 表达式.
- 编码器的输出是一个维度为 {n,ws,2} 的 3 阶张量,其中 n 是应用预处理后的分区的数量,ws 是计算中所用分区的长度. 最后一维表示结果的实部和虚部.
- 在构建网络时,可通过指定 "port"->NetEncoder[…] 将编码器添加到网络的输入端口上.
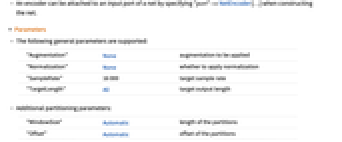
- 支持以下通用参数:
-
"Augmentation" None 是否应用增广 "Normalization" None 目标采样率 "SampleRate" 16000 目标采样率 "TargetLength" All 目标输出长度 - 其他分区参数:
-
"WindowSize" Automatic 分区的长度 "Offset" Automatic 分区的偏移 "WindowFunction" Automatic 应用于分区的视窗 - 可以为每个编码器参数指定以下设置和子选项.
- "Normalization" 可以接受以下设置:
-
None 无归一化 "Max" 绝对最大值归一化到 1 {"Max",val} 绝对最大值归一化到 val {"RMS",val} 输入音频信号的 RMS 归一化到 val - "TargetLength" 可以接受以下设置:
-
All 与输入信号一样 dur 持续时间 dur 被指定为时间量 n 前 n 个分区 - 如果指定的 "TargetLength" 不匹配输入信号的长度,则会进行填充或修剪.
- "Augmentation" 可用以下键被指定为规则列表:
-
"Convolution" None 在输入卷积脉冲响应 "Noise" None 在输入中添加噪声 "TimeShift" None 将输入移动指定的量 "Volume" None 用常量乘以输入 - 任何接受数值的增广参数也会被指定为两个数的列表或单变量分布. 在第一种情况下,会根据给定边界间的均匀分布随机化值. 在第二种情况,会使用用户提供的分布.
- "Convolution" 的可能值包括:
-
None 无增广 signal File 或 Audio 对象与输入卷积 {mix,signal} 与输入和 mix 参数卷积的信号 - "Noise" 可能的值包括:
-
None 无增广 amp 带有幅度 amp 的白噪声 noise File 或 Audio 对象包含要添加的噪声信号 {amp,noise} 噪声信号和其指定的幅度 - 使用 "TimeShift"->t 移动输入 t 秒、如果必要则进行填充或剪裁. 使用 Scaled[s] 移动输入 s×dur 秒,其中,dur 是输入信号的持续时间. 使用 {t1,t2} 或 Scaled[{ts1,t2}] 随机化指定时间之间的移动.
- 使用 "Volume"->val 指定常量乘数.
- 当参数为 "WindowSize"->Automatic 时,使用 25 毫秒分区长度. 使用 "WindowSize"->dur 选择持续时间 dur 的分区长度. 使用 "WindowSize"->n 选择 n 个样本的分区长度.
- 当参数为 "Offset"->Automatic 时,使用 8.33 毫秒的分区补偿. 使用 "Offset"->dur 选择持续时间 dur 的分区补偿. 使用 "Offset"->n 选择 n 个样本的分区补偿.
- 参数 "WindowFunction" 将窗口应用于每个分区. 可能的设置为:
-
None 没有视窗应用于输入音频 Automatic 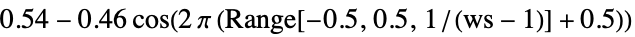
func 使用函数 func 计算视窗 list 明确指定采样窗口 list
参数
范例
打开所有单元关闭所有单元基本范例 (2)
范围 (3)
NetEncoder["AudioSTFT"] 可对 File 或 Audio 对象进行编码. 创建一个音频 STFT 编码器:
对 File 对象应用编码器:
对核内 Audio 对象应用该编码器:
对核外 Audio 对象应用该编码器:
创建 Audio 对象列表:
对一批输入应用 NetEncoder["AudioSTFT"]:
创建一个音频 STFT NetEncoder:
对 Audio 对象应用该网络:
Parameters (6)
"Normalization" (1)
"SampleRate" (2)
"TargetLength" (1)
"WindowSize" (1)
"Offset" (1)
属性和关系 (2)
创建一个 Audio 对象:
创建一个音频 STFT NetEncoder:
可用 Ceiling[length/offset] 来计算结果的长度,其中 length 是重新采样后信号的长度,offset 是编码器的 "Offset" 参数:
"AudioSTFT" 编码器的等价计算是基于 ShortTimeFourier: