NDSolve 的 “ExplicitRungeKutta” 方法
引言
欧拉方法
局部准确性是由多么高阶项与解的泰勒展开的匹配来衡量的. 欧拉方法是一阶准确的,因此误差从高一阶即 ![]() 的幂开始出现.
的幂开始出现.
欧拉方法的推广
朗格-库塔方法的思想是采用连续(加权)的欧拉步骤来对一个泰勒展开进行近似. 在这种方式下,使用的是函数计算(而非导数).
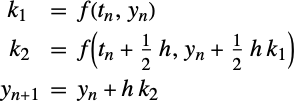
朗格-库塔方法
作为对 (1) 中的方法进行扩展,可以使用重复函数计算以获取高阶方法.
一般地,假设行-和条件(row-sum conditions)成立:
这些条件实际上确定了函数被采样的时间点,在推导高阶朗格-库塔方法上是一个特别有用的工具.
方法的系数是为了在时间步骤 ![]() 中满足某个阶数的泰勒展开而选择的自由参数. 在实际应用中,其它条件,比如稳定性也可以限制这些系数.
中满足某个阶数的泰勒展开而选择的自由参数. 在实际应用中,其它条件,比如稳定性也可以限制这些系数.
显式朗格-库塔方法是一个矩阵 ![]() 具有严格的下三角结构的特殊的情况:
具有严格的下三角结构的特殊的情况:
使用一个 Butcher 表格来表示方法系数 ![]() 、
、![]() 和
和 ![]() 已经成为一种惯例,它对于显式朗格-库塔方法具有如下格式:
已经成为一种惯例,它对于显式朗格-库塔方法具有如下格式:
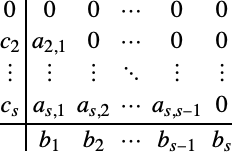
注意,显式的结果是 ![]() ,因此函数在当前积分步骤的开始时被采样.
,因此函数在当前积分步骤的开始时被采样.
示例
FSAL 方案
显式朗格-库塔方法的一个特别有趣的,用于大部分现代代码的特殊类型,是系数具有一种称为 First Same As Last (FSAL)的特殊结构的类型:
对于具一致性的 FSAL 方案,Butcher 表格(2)具有如下形式:

FSAL 方法的优点是在一个积分步骤末尾的函数值 ![]() 与下一个积分步骤的第一个函数值
与下一个积分步骤的第一个函数值 ![]() 相同.
相同.
当构建用于 NDSolve 中稠密输出的 InterpolatingFunction 时,要用到在每个积分步骤的开始和末尾的函数值.
嵌入对和局部误差估计
一个用于自适应步长控制的获取局部误差估计的有效方法是考虑具有不同阶数 ![]() 和
和 ![]() 的两种方法,它们共享同样的系数矩阵(因而同样的函数值).
的两种方法,它们共享同样的系数矩阵(因而同样的函数值).

在大部分现代代码中,包括在 NDSolve 中的默认选择,解是使用更准确的公式推进的,因而有 ![]() ,这被称为局部外插法.
,这被称为局部外插法.
系数的向量 ![]() 给出了一个误差估计器,以避免在计算(3) 和 (4) 之间的差异时,在浮点运算中
给出了一个误差估计器,以避免在计算(3) 和 (4) 之间的差异时,在浮点运算中 ![]() 的减法相消 .
的减法相消 .
步长控制
记号 ![]() 在 "NDSolve 中的范数" 中有解释.
在 "NDSolve 中的范数" 中有解释.
概况
阶数从 2(1) 到 9(8) 的显式朗格-库塔对已经被实现.
- 刚性检测功能(参阅 "刚性检测").
- 用于刚性和准刚性系统的比例-积分步长控制器 [G91].
在符合规定的要求下阶数为 2(1)、3(2) 和 4(3) 的最优公式对已经使用 Wolfram 语言推导得到,并且在 [SS04] 中描述.
该 5(4) 对由 Bogacki 和 Shampine 提供 [BS89b, S94] 而 6(5)、7(6)、8(7) 和 9(8) 对由 Verner [V10] 提供.
对于高阶对的选择,如局部截断误差比和稳定性区域兼容性等问题应予考虑(见 [S94]). 已经编写了各种工具来评估这些定性特征.
这些方法是可用互换的,这样,例如,可以使用 Dormand 和 Prince 方法替换 Bogacki 和 Shampine 的5(4)方法.
示例
方法比较
有时候,用户可能有兴趣找出在 NDSolve 中使用了什么方法.
用户还可能要比较一些不同的方法,看看它们对一个特定问题表现如何.
功用函数(Utilities)
用户可以使用一个功用函数 CompareMethods 来比较不同方法. 该函数用于比较方法的一些有用的 NDSolve 特征为:
- 选项 EvaluationMonitor,用来对函数计算的数目计数.
- 选项 StepMonitor,用来对被接受的和被拒绝的积分步进行计数.
参考解
在文献中的用于数值方法比较的大量例子依赖于一个事实,即存在一个解析解,这显然是相当有限的.
在 NDSolve 中,有可能使用任意精度自适应步长,得到非常准确的近似值;这是都是基于 "Extrapolation" 的自适应阶数方法.
自动阶数选择
当用户选择 "DifferenceOrder"->Automatic,该代码将自动尝试为积分选择最优阶数方法.
为了实现该目的,已经有两个算法被实现,并且在 "NDSolve 的 SymplecticPartitionedRungeKutta 方法" 中有描述.
示例 1
该默认方法具有阶数9,它与本例中8个阶数中的最优阶数相近. 在初始化阶段,需要一个函数计算来决定阶数.
示例 2
前面的例子的一个局限是它没有考虑由每个方法得到的解的准确性,因此它没有给出对成本的公平的反映.
与采用一个单一的容差来比较方法相反,最好使用一定范围的容差.
下面的例子是使用各种容差来比较具有不同阶数的各种 "ExplicitRungeKutta" 方法.
最优阶数在积分中可能会变化,从这一点讲,阶数选择算法是试探式的,但是正如例子所示,通常它会做一个合理的默认选择.
系数插入(Coefficient plug-in)
"ExplicitRungeKutta" 的实现在每个阶数提供了一个默认方法对.
经典朗格-库塔方法
该方法不具有嵌入式误差估计,因此没有系数误差向量的规格. 这意味着该调用方法时使用固定步长.
ode23
该三阶公式由 Ralston 提出,而嵌入式方法由 Bogacki 和 Shampine 导出[BS89a].
该方法用于德州仪器TI-85袖珍计算器(Texas Instruments TI-85 pocket calculator)、Matlab 和 RKSUITE 中 [S94]. 遗憾的是,它不允许已经选定的刚性检测的形式.
一个Fehlberg 方法
下面定义在六十年代流行的Fehlberg的一个 4(5) 显式朗格-库塔对的系数 [F69].
与四阶经典朗格-库塔方法相反,该系数包含用于误差估计的额外项.
该 Fehlberg 方法不是一个 FSAL 方案,因为系数矩阵不具有形式 (5);它是一个六阶段方案,但是在每步都需要六个函数计算,因为在步骤末尾需要函数计算以构建 InterpolatingFunction.
一个 Dormand-Prince 方法
下面显示如何定义 Dormand 和 Prince 系数的一个 5(4) 对[DP80]. 这是目前在Matlab中 ode45 所使用的方法.
Dormand–Prince方法是一个 FSAL 方案,因为系数矩阵具有形式 (6);它是一个七阶段方案,但是实际上只使用六个函数计算.
方法比较
方法插入(Method Plug-in)
这里显示如何使用方法插入环境实现经典四阶显式朗格-库塔方法.
请注意,该实现方法与在一本教科书中可能找到的描述非常相似. 例如,这里没有内存分配/释放语句或者类型声明. 事实上,该实现对于机器实数或者机器复数都适用,甚至对于使用任意精度的软件算法也适用.
为了提高效率,在内核中实现之前,在 NDSolve 中内置的许多方法首先使用顶层代码原型化.
刚性
例如,刚性可以出现在把扩散项通过差分(divided differences)翻译成一个大型常微分方程组中.
为了对刚性的本质有更深的理解,研究当应用于一个简单问题时方法如何表现是有用的.
线性稳定性
考虑把朗格-库塔方法应用到一个称为 Dahlquist 方程的线性标量方程中:
结果是一个由多项式 ![]() 组成的有理函数,其中
组成的有理函数,其中 ![]() (例如,参阅 [L87]).
(例如,参阅 [L87]).
该功用函数找到了朗格-库塔方法线的性稳定性函数 ![]() . 其形式取决于系数,并且如果朗格-库塔方法是显式的话,是一个多项式.
. 其形式取决于系数,并且如果朗格-库塔方法是显式的话,是一个多项式.
该函数找到了朗格-库塔方法的线性稳定性函数 ![]() . 该形式取决于系数,并且如果朗格-库塔方法是显式的话,是多项式的.
. 该形式取决于系数,并且如果朗格-库塔方法是显式的话,是多项式的.
取决于(7)中 ![]() 的大小,如果用户选择步长
的大小,如果用户选择步长 ![]() 使得
使得 ![]() ,那么,后续步骤中的误差将会衰减,该方法可以说是绝对稳定的.
,那么,后续步骤中的误差将会衰减,该方法可以说是绝对稳定的.
刚性检测
与选项 "StiffnessTest" 一同使用的刚性检测的设备在 "刚性检测" 中得到描述.
可以证明,差值 ![]() 对应于应用于
对应于应用于 ![]() 的幂方法(power method)的大量应用.
的幂方法(power method)的大量应用.
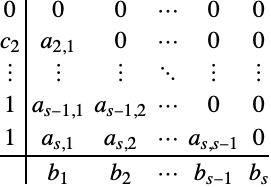
在 "ExplicitRungeKutta" 中使用的默认嵌入对都具有形式(10).
重要的一点是:(11)代价很低而且很方便;它使用积分的已有信息,不需要额外的函数计算.
(12) 的另一个优点是它直接使用一致 FSAL 方法 (13).
示例
一般来说,可能有一个以上的交叉点,因而它可能有必要选择合适的解.
Fehlberg 4(5) 方法没有刚性检测所要求的正确系数结构(2),因为 ![]() .
.
默认值 "StiffnessTest"->Automatic 检查方法系数是否提供了一个刚性检测的能力;如果有,那么刚性检测被启用.
再论步长控制
当考虑轻度刚性问题时,有理由来考查标准积分步控制器(1)的某些替代.
应用标准步长控制器求解一个刚性或者轻度刚性问题会导致大振荡,有时会导致一些不良的步拒绝.
它可以通过在一个嵌入式对中对高阶和低阶方法进行线性稳定性区域匹配来研究.
解决振荡的一个办法是推导特殊方法,但是这将使局部准确性打折扣.
PI 步长控制
积分步长控制(15)的一个令人感兴趣的替代是比例积分(Proportional-Integral)或者 PI 步长控制.
注意到积分步长控制(16)是(17)的一个特殊情况,并且在一个步骤被拒绝时采用:
选项 "StepSizeControlParameters"->{k1,k2} 可以用来指定 k1 和 k2 的值.
示例
刚性问题
定义一个类似于 IERK 的方法,使用选项 "StepSizeControlParameters" 来指明一个 PI 控制器.
非刚性问题
一般说来,I 步长控制器(19)能够对一个非刚性问题采取比 PI 步长控制器(20)更大的步长,如下面例子所示.
由于这个原因,"StepSizeControlParameters" 的默认设置是 Automatic,它可以解释为:
- 如果 "StiffnessTest"->False,采用 I 步长控制器(21) .
- 如果 "StiffnessTest"->True,采用 PI 步长控制器(22) .
微调
代替直接使用(23),通常的做法是使用安全因子,以确保误差在下一个步骤有很高的概率可以被接受,从而防止不必要的步骤拒绝.
选项 "StepSizeSafetyFactors"->{s1,s2} 指定在步长估计中使用的安全因子,这样(24)变成:
这里 s1 是一个绝对因子,而 s2 的大小通常随着方法的阶数改变.
选项 "StepSizeRatioBounds"->{srmin,srmax} 指定采取的下一个步长的边界,以满足:
选项总结
选项名 | 默认值 | |
| "Coefficients" | EmbeddedExplicitRungeKuttaCoefficients | 指定显式朗格-库塔方法的系数 |
| "DifferenceOrder" | Automatic | 指定局部准确度的阶数 |
| "EmbeddedDifferenceOrder" | Automatic | 指定在一对显式朗格-库塔方法中嵌入的方法的阶数 |
| "StepSizeControlParameters" | Automatic | 指定 PI 步长控制参数(见(25)) |
| "StepSizeRatioBounds" | { | 指定在新的步长中一个相对改变的界限(见(26)) |
| "StepSizeSafetyFactors" | Automatic | 指定在步长估计中使用的安全因子 (见(27)) |
| "StiffnessTest" | Automatic | 指定是否采用刚性检测功能 |
选项 "DifferenceOrder" 的默认设置 Automatic 基于问题、初值和局部误差容差选择默认系数阶数,以达到每个系数集合的方法的工作的平衡.
选项 "EmbeddedDifferenceOrder" 的默认设置 Automatic 指明嵌入式方法的默认阶数比方法阶数低一级. 这取决于 "DifferenceOrder" 选项的值.
选项 "StepSizeControlParameters" 的默认设置 Automatic 在刚性检测处于激活状态下使用值 {1,0},否则使用 {3/10,2/5}.
选项 "StepSizeSafetyFactors" 的默认设置 Automatic 在采用 I 步长控制器时使用值 {17/20,9/10},在采用 PI 步长控制器(28)时使用值 {9/10,9/10}. 使用的步控制器取决于选项 "StepSizeControlParameters" 和 "StiffnessTest" 的值.
选项 "StiffnessTest" 的默认设置 Automatic 将启动刚性测试,如果系数具有形式(29).