ニューラルネットワークを使った列学習と自然言語処理
「列学習」とは,ニューラルネットを訓練して実行させることのできるさまざまな関連タスクを指す.これらのタスクに共通なのは,ネットへの入力がある種の列となっていることである.この入力は通常可変長である.つまり,ネットは短い列でも長い列でも同様にうまく動作するということである.
- "Characters"か"Tokens" NetDecoderを使って列から符号化される可変長配列
- "Audio","AudioSpectrogram","AudioSTFT" NetDecoder等を使ってAudioオブジェクトから符号化される可変長配列
- "TargetLength" NetDecoderオプションを使う等した,上記のものの可変長の形
- 特定の列 x の確率
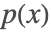 をモデル化するのに使われる「自己回帰言語モデル」では,出力は列の次の要素である.テキストモデルの場合,これは"Class","Characters","Token" NetDecoderで復号化される文字かトークンである.
をモデル化するのに使われる「自己回帰言語モデル」では,出力は列の次の要素である.テキストモデルの場合,これは"Class","Characters","Token" NetDecoderで復号化される文字かトークンである.
- 「列タグ付け」モデルでは,出力は入力と同じ長さのクラスの列となる.例えば,品詞のタグ付けの場合,これらのクラスは"Noun","Verb"となる.この場合"Class" NetDecoderが適切である.
- 英語からフランス語への翻訳器等の「翻訳」モデルでは,ソースの列を条件とするが,出力自体は言語モデルである.換言すれば,ネットに完全なソース列と「これまでの」ターゲット列の2つの入力があり,出力はターゲット列の次の要素の予測となる.
- 「CTC」モデルでは,入力列はターゲット列の断続的な予測の列を形成するために使われる.ターゲット列は常に入力列より短い.この例として,画素やデータやストロークデータからの手書き文字認識があり,入力は個々の文字に分けられる.その他に音声の転写もあり,音声の特徴は文字か音素に分けられる.これらには"CTCBeamSearch" NetDecoderを使う必要がある.
整数の加算
ここの例では,ネットは2桁の整数2つを足すよう訓練される.入力が数値ではなく数列であるのに対して出力は数値という点が難しいところである.例えば,ネットは入力"25+33"を取り,58に近い実数を返す必要がある.訓練データには長さ3 ("5+5"),長さ4 ("5+10"),長さ5 ("10+10")の例が含まれているので,入力は可変長である.
感情分析
Sequence-to-sequence学習は,入力と予測される出力の両方が列である学習タスクである.例えばドイツ語から英語への翻訳,音声ファイルからの書出し,数のリストの並べ替え等がこのタスクに当たる.
固定長の出力を伴う整数の加算
可変長の出力を伴う整数の加算
ここでは,入出力が両方とも可変長の数列であり,それらが同一ではない文字列でネットを訓練する方法を説明する.このタスクの高度な例として,英語をドイツ語に翻訳するというものがあるが,ここではもっと単純に,"250+123"等の総和を記述する数列を取り,"373"等の答を記述する出力数列を生成するというものにする.使用されるメソッドはI. Sutskeverその他による2014年の論文「Sequence to Sequence Learning with Neural Networks」を基にしている.
列の最初と最後に特別なコードを使うNetEncoderを作成する.これは出力列の最初と最後を示すのに使われる:
CrossEntropyLossLayerおよびエンコーダネットとデコーダネットを持つネットを定義する:
より効率的に予測を求めるには,EndOfString仮想文字に達するまで出力を生成し続ける.
まず訓練されたNetGraphから,訓練された「エンコーダ」と「デコーダ」のサブネットを抽出し,適切なエンコーダとデコーダを加える:
SequenceLastLayerを使って,前の文字が与えられたときに答の最後の文字だけを予測するデコーダのバージョンを作成する.「ターゲット」入力と同じアルファベットを使って,確率ベクトルの文字デコーダが追加される:
次の文字を得るためにそれぞれの部分的な答をデコーダに渡すことによって生成する初歩的な方法には,n2の時間的コストがある.ここでn は出力の長さであるため,長い列の生成には適さない.NetStateObjectを使うと n の時間的コストを伴って生成することができる.
1文字を取り,GatedRecurrentLayerを1ステップ実行し,1つのsoftmax予測を生成するネットを定義する:
この予測子は,Informationで分かるように,内部的な回帰状態を持っている:
訓練されたエンコーダによって生成されるコードから種を播かれるNetStateObjectを使って内部的な再帰状態を記憶する関数を生成する:
整数の並べ替え
この例では,ネットを訓練して整数のリストを並べ替える.例えば,ネットは入力{3,2,4}を取って{2,3,4}を返さなければならないのである.この例は,多数の数列学習タスクにおけるニューラルネットの性能を大きく向上させるAttentionLayerの使い方も示す.
Toyデータセットの光学文字認識(OCR)
光学文字認識問題では,文字列を含む画像を取り,文字のリストを返す.その方法の例として,1つの文字だけを含む画像を生成するために画像を前処理し,分類を行うというものがある.これは不安定な方法であり,文字がくっついている筆記体等では全くうまくいかない.
訓練集合のRandomSampleを取る:
bAbI QAデータセットで訓練された回帰型ニューラルネットワークのサンプル
bAbI QAデータセットで訓練されたメモリネットワーク
Sukhbaatarらによる2015年の論文「End-to-End Memory Networks」に基づいたメモリネットワークを使って,bAbI QAデータセットの最初のタスク(Single Supporting Fact)で質問応答ネットを訓練する.
メモリネットには可変長の例を現在サポートしない層(TransposeLayer等)がある.
文字レベルの言語モデル
ネットを訓練する.これはCPUでは最大1時間かかるので,NVIDIAグラフィックスカードが利用できる場合はTargetDevice->"GPU"を使う.最近のGPUではこの例は訳7分で完了する:
最初のテキストが与えられたときに,次のテキスト100文字を生成する.この方法では,長い文字列を効率よく生成するためにNetStateObjectを使っている:
まず文字列全体を同時に予測するネットを構築する.このネットは,最後の要素を取って通常のベクトルソフトマックスを実行する代りに,LinearLayerがマップされ,行列のソフトマックスが実行されるという点で,先ほどの予測ネットと異なる:
ターゲットの文を取り,それをずらしてネットワークに提示する強制ネットワークを構築する.長さ26の文の場合,1から25までの文字をネットに提示し,ネットが文字2から26までの予測を行うようにするのである.この予測はCrossEntropyLossLayerを使って実際の文字と比較され損失が計算される:
最初のテキストが与えられたときに,テキスト100文字を生成する.この方法では,長いテキスト列を効率的に生成するためにNetStateObjectが使われる: