神经网络的序列学习和 NLP
- 变长度数组,编码自使用 "Characters" 或 "Tokens" NetEncoder 的字符串.
- 变长度数组,编码自使用 "Audio"、"AudioSpectrogram"、"AudioSTFT" 等 NetEncoder 的 Audio 对象.
- 以上固定长度的格式通过把 "TargetLength" 选项使用在 NetEncoder.
- 对于自回归语言模型,用于模拟特殊序列 x 的
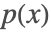 概率,输出是序列的下一个元素. 在文本模型的情况中,这是字符或令牌,通过 "Class"、"Characters" 或 "Token" NetDecoder 进行解码.
概率,输出是序列的下一个元素. 在文本模型的情况中,这是字符或令牌,通过 "Class"、"Characters" 或 "Token" NetDecoder 进行解码.
- 对于序列标记模型,输出是与输入同样长度额类序列. 例如,在词类标注器的情况下,这些类是 "Noun"、"Verb" 等. 这种情况下,"Class" NetDecoder 是适当的.
- 对于 CTC 模型,输入序列用于形成目标序列的间歇预测序列,该序列总是比输入序列短. 这方面的例子包括来自像素或笔划数据的手写识别,其中输入被分割成单独的字符或音频转录,音频的特征被分割成字符或音素. 这些必须使用 "CTCBeamSearch" NetDecoder.
整数相加
在该范例中,网络被培训成相加两个二位数的整数. 问题的困难所在是输入是字符串而不是数值,而输出是数值. 例如,网络接受输入 "25+33" 且需要返回接近 58 的实数. 注意,输入是可变长度,培训数据包括长度 3 ("5+5")、长度 4 ("5+10") 和长度 5 ("10+10") 的范例.
情绪分析
固定长度输出的整数相加
带有变长度输出的整数相加
该范例演示了如何在序列上培训网络,其中,输入和输出是变长度序列,且不一样. 该任务的一个复杂范例是把英文翻成德文,但是,我们要演示的范例是一个更简单的问题:接受一个描述和的字符串,例如:"250+123",并产生一个输出字符串描述答案,例如,"373". 该方法是基于 2014 年的 I. Sutskever 等写的, "Sequence to Sequence Learning with Neural Networks".
创建一个 NetEncoder,为字符串的起始和结尾使用特殊代码,这将被用于表明输出序列的起始和结束:
定义一个带有 CrossEntropyLossLayer 的网络,包含编码器和解码器网络:
获取预测更有效的方法是产生输出直到到达 EndOfString 可视化字符.
通过将每个部分答案传递给解码器网络以导出下一个字符而产生的幼稚技术具有 n2 的时间复杂度,其中 n 是输出序列的长度,因此不适合于生成更长的序列. NetStateObject 用于生成 n 的时间复杂度.
定义一个网络,接受单个字符,运行 GatedRecurrentLayer 的一个步骤并产生单个 softmax 预测:
该预测器由内部循环状态,由 Information 显示:
创建一个使用 NetStateObject 的函数,记住内部循环状态,它是由训练过的编码器产生的代码播种的:
整数排序
在该范例中,培训网络来排序整数列表. 例如,网络接受输入 {3,2,4} 并且需要返回 {2,3,4}. 该范例也演示了 AttentionLayer 的使用,它显著改善了神经网络在许多序列学习任务中的性能.
玩具数据集上的光字符识别 (OCR)
提取培训集的 RandomSample:
bAbI QA 数据集上简单的 RNN 培训
bAbI QA 数据集上的内存网络培训
在 bAbI QA 数据集上的第一个任务(单个支持事实)上培训问题-回答网络,使用的内存网络基于 2015 年的 Sukhbaatar 等的 "End-to-End Memory Networks".
内存网络有些不支持变长度序列的层(例如,TransposeLayer).
字符级语言模型
培训网络. 在 CPU 上大概需要 1 个小时,如果有 NVIDIA 图卡,就使用 TargetDevice->"GPU". 现代 GPU 大约 7 分钟就可以完成该范例:
给定起始文本,产生 100 个文本字符. 注意,该方法使用 NetStateObject 高效产生文本的长序列:
首先,构建预测整个序列的网络. 这个与之前的预测网络不同,之前是映射 LinearLayer 并执行矩阵 softmax,而不是采集最后元素,进行常规向量 softmax:
现在构建强迫网络,接受目标句子,并以“交错”形式展现在网络上:对于长度为 26 的句子,对网络展现字符 1 到 25,为字符 2 到 26 产生预测,通过 CrossEntropyLossLayer 比较真实字符产生损失:
给定起始文本,产生 100 个字符文本. 注意,该方法使用 NetStateObject 高效地产生长文本序列: