

TTest
詳細とオプション



- TTestは帰無仮説
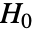 と対立仮説
と対立仮説 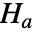 で検定を行う.
で検定を行う. -
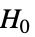
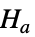
data 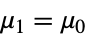
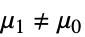
{data1,data2} 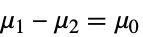
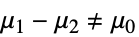
- ただし,μiは dataiの母平均である.
- デフォルトで,確率値つまり
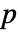 値が返される.
値が返される. - 小さい
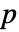 値は
値は 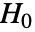 が真である可能性が低いことを示す.
が真である可能性が低いことを示す. - dspec 中のデータは一変量{x1,x2,…}でも多変量{{x1,y1,…},{x2,y2,…},…}でもよい.
- 引数 μ0は実数あるいはデータの次元と長さが等しい実ベクトルでよい.
- TTestはデータが正規分布に従うと仮定するが,この仮定についてかなり強力である.TTestはまた2つのサンプルがある場合はサンプルがそれぞれ独立であると仮定する.
- TTest[dspec,μ0,"HypothesisTestData"]はHypothesisTestDataオブジェクト htd を返す.これは htd["property"]として追加的な検定結果と特性の抽出に使うことができる.
- TTest[dspec,μ0,"property"]を使って直接"property"の値を与えることができる.
- 検定結果のレポートに関連する特性
-
"DegreesOfFreedom" 検定で使用される自由度 "PValue" 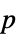 値のリスト
値のリスト "PValueTable" 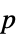 値のフォーマットされた表
値のフォーマットされた表"ShortTestConclusion" 検定結果の簡単な説明 "TestConclusion" 検定結果の説明 "TestData" 検定統計と 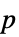 値のペアのリスト
値のペアのリスト"TestDataTable" 検定統計と 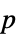 値のフォーマットされた表
値のフォーマットされた表"TestStatistic" 検定統計のリスト "TestStatisticTable" 検定統計のフォーマットされた表 - 一変量のサンプルの場合,TTestはスチューデント
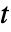 検定を行う.検定統計はStudentTDistribution[df]に従うと仮定される.
検定を行う.検定統計はStudentTDistribution[df]に従うと仮定される. - 多変量のサンプルの場合,TTestはHotellingの
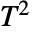 検定を行う.検定統計はHotellingTSquareDistribution[p,df]に従うと仮定される.ただし,p は data の次元である.
検定を行う.検定統計はHotellingTSquareDistribution[p,df]に従うと仮定される.ただし,p は data の次元である. - 検定統計の分布指定に使われる自由度 df は,サンプルの大きさ,サンプル数,さらに2つの一変量サンプルの場合は分散が等しいかどうかの検定結果に依存する.
- 使用可能なオプション
-
AlternativeHypothesis "Unequal" 対立仮説のための不等式 SignificanceLevel 0.05 診断と報告のための切捨て VerifyTestAssumptions Automatic どの仮定を検証するか - TTestでは,
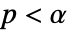 のときにのみ
のときにのみ 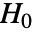 が棄却されるような切捨て
が棄却されるような切捨て 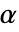 が選択される.特性"TestConclusion"および"ShortTestConclusion"で使われる
が選択される.特性"TestConclusion"および"ShortTestConclusion"で使われる 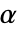 の値はSignificanceLevelオプションで制御される.
の値はSignificanceLevelオプションで制御される.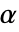 の値は,正規性,等分散,対称性の検定を含む仮定の診断検定にも使われる.デフォルトで
の値は,正規性,等分散,対称性の検定を含む仮定の診断検定にも使われる.デフォルトで 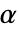 は0.05に設定される.
は0.05に設定される. - TTestにおけるVerifyTestAssumptionsの名前付き設定
-
"Normality" すべてのデータが正規分布に従うことを検証する "EqualVariance" data1と data2が等分散であることを検証する
例題
すべて開く すべて閉じる例 (3)
スコープ (13)
検定 (10)
Automaticを使うことは,ゼロの平均について検定することと同じである:
多変量データ集合の平均ベクトルがゼロベクトルであるかどうかを検定する:
2つの多変量データ集合の平均差分ベクトルがゼロベクトルであるかどうかを検定する:
繰り返し特性を抽出するためにHypothesisTestDataオブジェクトを作成する:
HypothesisTestDataオブジェクトから特性を抽出する:
オプション (11)
アプリケーション (4)
光の通過速度の3つ目の一連の測定値は,1882年にニューコム(Newcomb)よって記録された.与えられた値を1000で割って24加えたものは,既知の距離を光が移動する時間(単位:100万分の1秒)を与える.現在のところ,真の値は33.02であると考えられている:
ショーブネ(Chauvenet)の基準を使って外れ値を識別する:
データの大部分について ![]() 検定を行うと,ニューコムの光速度の測定値は実際の値よりもかなり低いことが分かる:
検定を行うと,ニューコムの光速度の測定値は実際の値よりもかなり低いことが分かる:
2つの実験的なキャベツの栽培品種それぞれから30個のサンプルについてビタミンCの量と全体の重さを記録した:
重さのデータはc52については正規分布に従わないので,MannWhitneyTestを使って軽いキャベツの方がずっと多くのビタミンCを含むことを示す:
アヤメの花の3つの種のそれぞれから50のサンプルが集められた.サンプルは,アヤメの萼片と花弁の長さと幅の測定値からなる.virginica および versicolor の種を区別することは難しい:
特性と関係 (11)
一変量データについては,![]() において検定統計はStudentTDistributionに従う:
において検定統計はStudentTDistributionに従う:
多変量データについては,![]() において検定統計はHotellingTSquareDistributionに従う:
において検定統計はHotellingTSquareDistributionに従う:
等しくない分散を持つ2つのサンプル(サタスウェイト(Satterthwaite)近似):
使用される自由度のタイプはVerifyTestAssumptionsを使って制御できる:
Satterthwaite近似を使うために明示的に不等分散を仮定する:
多変量データについては,Hotellingの ![]() 統計の計算に平方マハラノビス(Mahalanobis)距離が使われる:
統計の計算に平方マハラノビス(Mahalanobis)距離が使われる:
![]() においては,検定統計はHotellingTSquareDistribution[p,n-1]に従う:
においては,検定統計はHotellingTSquareDistribution[p,n-1]に従う:
母分散が既知である場合には,より強力なZTestを使うことができる:
TTestは正規性からの少しの偏差に対して強固である:
正規性からの大きい偏差には,中央値に基づく検定を使う必要がある:
![]() 値は,SignedRankTestについては通常通りに解釈することができるが,TTestについてはできない:
値は,SignedRankTestについては通常通りに解釈することができるが,TTestについてはできない:
正規性のないデータの2つのサンプルの検定にはMannWhitneyTestを使う:
正規性のないデータにはMannWhitneyTestの方がTTestよりも強力であることがある:
TTestは,入力がTimeSeriesのときにのみ値に使うことができる:
TTestは,入力がTemporalDataのときはすべての値に使うことができる:
考えられる問題 (2)

テキスト
Wolfram Research (2010), TTest, Wolfram言語関数, https://reference.wolfram.com/language/ref/TTest.html.
CMS
Wolfram Language. 2010. "TTest." Wolfram Language & System Documentation Center. Wolfram Research. https://reference.wolfram.com/language/ref/TTest.html.
APA
Wolfram Language. (2010). TTest. Wolfram Language & System Documentation Center. Retrieved from https://reference.wolfram.com/language/ref/TTest.html