

LocationEquivalenceTest
LocationEquivalenceTest[{data1,data2,…}]
tests whether the means or medians of the datai are equal.
LocationEquivalenceTest[{data1,…},"property"]
returns the value of "property".
Details and Options
- LocationEquivalenceTest performs a hypothesis test on the datai with null hypothesis
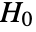 that the true location parameters of the populations are equal,
that the true location parameters of the populations are equal, 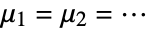 , and alternative hypothesis
, and alternative hypothesis 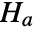 that at least one is different.
that at least one is different. - By default, a probability value or
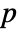 -value is returned.
-value is returned. - A small
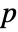 -value suggests that it is unlikely that
-value suggests that it is unlikely that 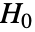 is true.
is true. - The datai must be univariate {x1,x2,…}.
- LocationEquivalenceTest[{data1,…}] will choose the most powerful test that applies to the data.
- LocationEquivalenceTest[{data1,…},All] will choose all tests that apply to the data.
- LocationEquivalenceTest[{data1,…},"test"] reports the
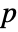 -value according to "test".
-value according to "test". - Mean-based tests assume that the datai are normally distributed. The median-based Kruskal–Wallis test assumes that datai are symmetric about a common median. The complete block
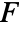 and Friedman rank tests assume that the data is in randomized complete blocks. All of the tests require the datai to have equal variances.
and Friedman rank tests assume that the data is in randomized complete blocks. All of the tests require the datai to have equal variances. - The following tests can be used:
-
"CompleteBlockF" normality, blocked mean test for complete block design "FriedmanRank" blocked median test for complete block design "KruskalWallis" symmetry median test for two or more samples "KSampleT" normality mean test for two or more samples - The complete block
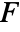 test effectively performs one-way analysis of variance for randomized complete block design.
test effectively performs one-way analysis of variance for randomized complete block design. - The Friedman rank test ranks observations across rows and sums the ranks along columns in the data to arrive at the test statistic. The statistic is corrected for ties.
- The Kruskal–Wallis test effectively performs a one-way analysis of variance on the ranks of the data. The test statistic is corrected for ties.
- The
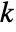 -sample
-sample 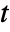 -test is equivalent to a one-way analysis of variance of the data.
-test is equivalent to a one-way analysis of variance of the data. - LocationEquivalenceTest[{data1,…},"HypothesisTestData"] returns a HypothesisTestData object htd that can be used to extract additional test results and properties using the form htd["property"].
- LocationEquivalenceTest[{data1,…},"property"] can be used to directly give the value of "property".
- Properties related to the reporting of test results include:
-
"AllTests" list of all applicable tests "AutomaticTest" test chosen if Automatic is used "DegreesOfFreedom" the degrees of freedom used in a test "PValue" list of 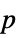 -values
-values"PValueTable" formatted table of 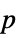 -values
-values"ShortTestConclusion" a short description of the conclusion of a test "TestConclusion" a description of the conclusion of a test "TestData" list of pairs of test statistics and 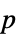 -values
-values"TestDataTable" formatted table of 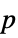 -values and test statistics
-values and test statistics"TestStatistic" list of test statistics "TestStatisticTable" formatted table of test statistics - The following options can be given:
-
Method Automatic the method to use for computing 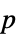 -values
-valuesSignificanceLevel 0.05 cutoff for diagnostics and reporting VerifyTestAssumptions Automatic what assumptions to verify - For tests of location, a cutoff
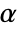 is chosen such that
is chosen such that 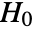 is rejected only if
is rejected only if 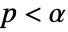 . The value of
. The value of 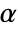 used for the "TestConclusion" and "ShortTestConclusion" properties is controlled by the SignificanceLevel option. This value
used for the "TestConclusion" and "ShortTestConclusion" properties is controlled by the SignificanceLevel option. This value 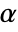 is also used in diagnostic tests of assumptions, including tests for normality, equal variance, and symmetry. By default,
is also used in diagnostic tests of assumptions, including tests for normality, equal variance, and symmetry. By default, 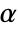 is set to 0.05.
is set to 0.05. - Named settings for VerifyTestAssumptions in LocationEquivalenceTest include:
-
"Normality" verify that all data is normally distributed "EqualVariance" verify that the datai have equal variances "Symmetry" verify symmetry about a common median
Examples
open all close allBasic Examples (3)
Test whether the means or medians from two or more populations are all equivalent:
data1 = RandomVariate[NormalDistribution[.25, 1], 100];
data2 = RandomVariate[NormalDistribution[0, 1], 150];
data3 = RandomVariate[NormalDistribution[0, 1], 135];LocationEquivalenceTest[{data1, data2, data3}, {"TestDataTable", All}]Create a HypothesisTestData object for repeated property extraction:
ℋ = LocationEquivalenceTest[{data1, data2, data3}, "HypothesisTestData"]ℋ["Properties"]The complete block ![]() test can be used to test for mean differences with complete block design:
test can be used to test for mean differences with complete block design:
data = {{36.05, 52.47, 56.55, 45.2, 35.25, 66.38, 40.57, 57.15, 28.34}, {42.47, 85.15, 63.20, 52.10, 66.20, 73.25, 44.50, 57.17, 35.05}, {51.50, 65, 73.1, 64.4, 57.45, 76.49, 40.55, 66.47, 33.17}, {37.55, 59.3, 79.12, 58.33, 70.54, 69.47, 46.48, 66.35, 36.2}};SmoothHistogram[data, 20]Mean /@ dataThere is a significant difference among the means at the 0.05 level:
LocationEquivalenceTest[data, {"TestDataTable", "CompleteBlockF"}]Use the Friedman rank test to test for differences in medians with complete block design:
data = {{70, 77, 76, 80, 84, 78}, {61, 75, 67, 63, 66, 68}, {82, 88, 90, 96, 92, 98}, {74, 76, 80, 76, 84, 86}};SmoothHistogram[data, 10]Mean /@ data//NIt appears that at least one median differs significantly from the others:
LocationEquivalenceTest[data, {"TestDataTable", "FriedmanRank"}]Scope (9)
Testing (5)
Perform a particular test for equal locations:
data = RandomVariate[NormalDistribution[], {2, 10^3}];LocationEquivalenceTest[data, "KSampleT"]Any number of tests can be performed simultaneously:
LocationEquivalenceTest[data, {"KSampleT", "KruskalWallis"}]Perform all tests appropriate to the data simultaneously:
data = RandomVariate[NormalDistribution[], {5, 250}];LocationEquivalenceTest[data, All]Use the property "AllTests" to identify which tests were used:
LocationEquivalenceTest[data, "AllTests"]Create a HypothesisTestData object for repeated property extraction:
data = RandomVariate[NormalDistribution[], {3, 10^4}];ℋ = LocationEquivalenceTest[data, "HypothesisTestData"];The properties available for extraction:
ℋ["Properties"]Extract some properties from a HypothesisTestData object:
data = RandomVariate[NormalDistribution[], {3, 10^2}];ℋ = LocationEquivalenceTest[data, "HypothesisTestData"];The ![]() -value and test statistic from a
-value and test statistic from a ![]() -sample
-sample ![]() -test:
-test:
ℋ["PValue", "KSampleT"]ℋ["TestStatistic", "KSampleT"]Extract any number of properties simultaneously:
data = RandomVariate[NormalDistribution[], {3, 10^3}];ℋ = LocationEquivalenceTest[data, "HypothesisTestData"];The ![]() -value and test statistic from a Kruskal–Wallis test:
-value and test statistic from a Kruskal–Wallis test:
ℋ[{{"PValue", "KruskalWallis"}, {"TestStatistic", "KruskalWallis"}}]Reporting (4)
Tabulate the results from a selection of tests:
data = RandomVariate[NormalDistribution[], {4, 20}];ℋ = LocationEquivalenceTest[data, "HypothesisTestData"];ℋ["TestDataTable", "KSampleT"]A full table of all appropriate test results:
ℋ["TestDataTable", All]A table of selected test results:
ℋ["TestDataTable", {"KSampleT", "KruskalWallis"}]Retrieve the entries from a test table for customized reporting:
data = BlockRandom[SeedRandom[2];RandomVariate[NormalDistribution[], {2, 10^3}]];ℋ = LocationEquivalenceTest[data, "HypothesisTestData"];res = ℋ["TestData", All];tests = ℋ["AllTests"]The ![]() -values are above 0.05, so there is not enough evidence to reject
-values are above 0.05, so there is not enough evidence to reject ![]() at that level:
at that level:
Show[BarChart[res[[All, 2]], ChartLabels -> Placed[tests, Center], BarOrigin -> Left], Graphics[{Dashed, InfiniteLine[{{.05, 0}, {.05, 1}}]}]]Tabulate ![]() -values for a test or group of tests:
-values for a test or group of tests:
data = RandomVariate[NormalDistribution[], {2, 10^2}];ℋ = LocationEquivalenceTest[data, "HypothesisTestData"];ℋ["PValueTable", "KSampleT"]ℋ["PValue", "KSampleT"]A table of ![]() -values from all appropriate tests:
-values from all appropriate tests:
ℋ["PValueTable", All]A table of ![]() -values from a subset of tests:
-values from a subset of tests:
ℋ["PValueTable", {"KSampleT", "KruskalWallis"}]Report the test statistic from a test or group of tests:
data = RandomVariate[CauchyDistribution[1, 2], {2, 10^3}];ℋ = LocationEquivalenceTest[data, "HypothesisTestData"];ℋ[Automatic]The test statistic from the table:
ℋ["TestStatistic"]A table of test statistics from all appropriate tests:
ℋ["TestStatisticTable", All]Options (8)
Method (2)
Compute the Kruskal–Wallis test for a group of datasets:
data = RandomVariate[NormalDistribution[], {5, 100}];{χ, p} = LocationEquivalenceTest[data, {"TestData", "KruskalWallis"}]The rescaled test statistic follows an FRatioDistribution:
fFromChi[χ_, n_, g_] := ((n - g)χ/(g - 1)(n - 1 - χ))SurvivalFunction[FRatioDistribution[4, 495], fFromChi[χ, 500, 5]]Use the asymptotic chi-square approximation:
{χ, p} = LocationEquivalenceTest[data, {"TestData", "KruskalWallis"}, Method -> "Asymptotic"]SurvivalFunction[ChiSquareDistribution[4], χ]Use the asymptotic chi-square distribution for the Friedman rank test:
data = RandomVariate[NormalDistribution[], {5, 100}];LocationEquivalenceTest[data, {"TestDataTable", "FriedmanRank"}, Method -> "Asymptotic"]By default, Conover's ![]() -distribution approximation is used:
-distribution approximation is used:
LocationEquivalenceTest[data, {"TestDataTable", "FriedmanRank"}]SignificanceLevel (3)
Set the significance level for diagnostic tests:
data = BlockRandom[SeedRandom[2];RandomVariate[StudentTDistribution[3], {3, 50}]];LocationEquivalenceTest[data, "KSampleT", SignificanceLevel -> .005]LocationEquivalenceTest[data, "KSampleT", SignificanceLevel -> Automatic]Setting the significance level may alter which test is automatically chosen:
data = BlockRandom[SeedRandom[1];RandomVariate[StudentTDistribution[3], {3, 50}]];LocationEquivalenceTest[data, "AutomaticTest", SignificanceLevel -> .005]A median-based test would have been chosen by default:
LocationEquivalenceTest[data, "AutomaticTest", SignificanceLevel -> Automatic]The significance level is also used for "TestConclusion" and "ShortTestConclusion":
BlockRandom[SeedRandom[1];data1 = RandomVariate[NormalDistribution[.1, 1], 500];
data2 = RandomVariate[NormalDistribution[.1, 1], 500];
data3 = RandomVariate[NormalDistribution[0, 1], 500]];LocationEquivalenceTest[{data1, data2, data3}, "TestConclusion", SignificanceLevel -> .005]//TraditionalFormLocationEquivalenceTest[{data1, data2, data3}, "TestConclusion", SignificanceLevel -> .05]//TraditionalFormLocationEquivalenceTest[{data1, data2, data3}, "ShortTestConclusion", SignificanceLevel -> .005]LocationEquivalenceTest[{data1, data2, data3}, "ShortTestConclusion", SignificanceLevel -> .05]VerifyTestAssumptions (3)
Diagnostics can be controlled as a group using All or None:
data = RandomVariate[StudentTDistribution[3], {4, 1000}];LocationEquivalenceTest[data, "KSampleT", VerifyTestAssumptions -> All]LocationEquivalenceTest[data, "KSampleT", VerifyTestAssumptions -> None]Diagnostics can be controlled independently:
data = RandomVariate[StudentTDistribution[3], {4, 1000}];Assume normality but check for symmetry:
LocationEquivalenceTest[data, "KSampleT", VerifyTestAssumptions -> "Symmetry"]LocationEquivalenceTest[data, "KSampleT", VerifyTestAssumptions -> "Normality"]Test assumption values can be explicitly set:
data = RandomVariate[CauchyDistribution[0, 1], {3, 100}];LocationEquivalenceTest[data, "TestDataTable"]LocationEquivalenceTest[data, "TestDataTable", VerifyTestAssumptions -> "Normality" -> True]The Kruskal-Wallis test was previously chosen because the data is not normally distributed:
LocationEquivalenceTest[data, {"TestDataTable", "KSampleT"}]Applications (4)
Test whether a group of populations shares a common location:
data1 = Table[RandomVariate[NormalDistribution[μ, 1], 100], {μ, RandomReal[{-3, 3}, 8]}];data2 = Table[RandomVariate[NormalDistribution[μ, 1], 100], {μ, RandomReal[{-.05, .05}, 8]}];{BoxWhiskerChart[data1], BoxWhiskerChart[data2]}The first group of datasets was drawn from populations with very different locations:
LocationEquivalenceTest[data1, "TestDataTable"]Populations represented by the second group all have similar locations:
LocationEquivalenceTest[data2, "TestDataTable"]Morphological measures of two crab varieties were taken for each of the two sexes. Determine whether the measures differ across the various groups:
ExampleData[{"Statistics", "CrabMeasures"}, "ColumnDescriptions"]{variety, gender, FL, RW, CL, CW} = Transpose[ExampleData[{"Statistics", "CrabMeasures"}][[All, {1, 2, 4, 5, 6, 7}]]];MapThread[SmoothHistogram[Table[Pick[#1, gender, sp], {sp, DeleteDuplicates[gender]}], PlotLabel -> #2, Ticks -> None]&, {{FL, RW, CL, CW}, {"Frontal Lobe", "Rear Width", "Carapace Length", "Carapace Width"}}]The rear width is the only measure that differs by gender when variety is ignored:
LocationEquivalenceTest[Table[Pick[#, gender, sp], {sp, DeleteDuplicates[gender]}], "TestDataTable"]& /@ {FL, RW, CL, CW}MapThread[SmoothHistogram[Table[Pick[#1, Transpose[{variety, gender}], sp], {sp, DeleteDuplicates[Transpose[{variety, gender}]]}], PlotLabel -> #2, Ticks -> None]&, {{FL, RW, CL, CW}, {"Frontal Lobe", "Rear Width", "Carapace Length", "Carapace Width"}}]All measures are significantly different when gender and variety are considered simultaneously:
LocationEquivalenceTest[Table[Pick[#, Transpose[{variety, gender}], sp], {sp, DeleteDuplicates[Transpose[{variety, gender}]]}], "TestDataTable"]& /@ {FL, RW, CL, CW}A pilot study was conducted for 75 patients with type II diabetes who had failed to achieve target weight loss with a particular medication. The patients were randomly assigned to three groups: a control group continuing the original medication, and two treatment groups that received 50 and 100 mg of a new medication, respectively. Weight loss in pounds over a 12-week period was recorded:
control = {-1.2, 0.8, -0.4, 1.5, 1.7, 0.1, 0.9, 0.5, 1.9, 2.3, -0.2, 0.1, 1.7, 1.5, 0.5, 1.9, 2.1, 0.1, 2.4, 0.9, 0., 1.7, 1.9, 0.2, 2.2};treat50 = {3.4, 4.9, 3.2, 6.2, 2.7, 2.7, 3.7, 6.1, 4.6, 5.7, 4.1, 5.3, 5.9, 5.0, 7.1, 5.0, 4.7, 5.6, 6.3, 2.0, 5.8, 8.2, 6.5, 7.1, 4.7};treat100 = {1.5, 2.0, 1.0, 3.7, 5.7, 3.7, 6.1, 4.5, 7.1, 2.9, 3.1, 4.6, 6.4, 5.1, 5.5, 6.1, 5.1, 6.1, 1.4, 1.5, 5.4, 3.8, 3.1, 3.2, 2.7};SmoothHistogram[{control, treat50, treat100}, Frame -> True, Axes -> None, PlotLegends -> {"control", "treat50", "treat100"}]There is a significant difference in the means of the groups:
LocationEquivalenceTest[{control, treat50, treat100}, "TestDataTable"]Using a Bonferroni correction in a test of each pairwise difference shows that both treatment levels perform better than the control, but that they are not significantly different from one another:
α = 0.05;LocationEquivalenceTest[{control, treat50}, "ShortTestConclusion", SignificanceLevel -> α / 3]LocationEquivalenceTest[{control, treat100}, "ShortTestConclusion", SignificanceLevel -> α / 3]//QuietLocationEquivalenceTest[{treat50, treat100}, "ShortTestConclusion", SignificanceLevel -> α / 3]A group of six food critics rated four restaurants for quality on a 100-point scale. Determine whether there is a significant difference in the quality of the restaurants according to critics:
data = {{70, 77, 76, 80, 84, 78}, {61, 75, 67, 63, 66, 68}, {82, 88, 90, 96, 92, 98}, {74, 76, 80, 76, 84, 86}};Bar charts of the median score by critic:
BarChart[Median[data], ChartLabels -> {"C1", "C2", "C3", "C4", "C5", "C6"}]Bar charts of the median score for each restaurant:
BarChart[Median /@ data, ChartLabels -> {"A", "B", "C", "D"}]Accounting for the blocked structure, a significant difference in quality can be detected:
LocationEquivalenceTest[data, {"TestDataTable", {"FriedmanRank", "CompleteBlockF"}}]Properties & Relations (12)
The ![]() -value returned by a
-value returned by a ![]() -sample
-sample ![]() -test is equivalent to that of TTest for two samples:
-test is equivalent to that of TTest for two samples:
data = RandomVariate[NormalDistribution[], {2, 100}];LocationEquivalenceTest[data, {"PValueTable", "KSampleT"}]TTest[data, 0, "PValueTable", VerifyTestAssumptions -> None]The Kruskal–Wallis test is a ![]() -sample extension of the two-sample Mann–Whitney test:
-sample extension of the two-sample Mann–Whitney test:
data = RandomVariate[NormalDistribution[], {2, 1000}];LocationEquivalenceTest[data, {"PValueTable", "KruskalWallis"}]The Mann–Whitney ![]() -value is corrected for continuity and ties:
-value is corrected for continuity and ties:
MannWhitneyTest[data, 0, "PValueTable"]Under ![]() the
the ![]() -sample
-sample ![]() -test statistic follows an FRatioDistribution[g-1,n-g], where g is the number of datasets and n is the total number of observations:
-test statistic follows an FRatioDistribution[g-1,n-g], where g is the number of datasets and n is the total number of observations:
data = RandomVariate[NormalDistribution[], {1000, 3, 200}];kst = LocationEquivalenceTest[#, {"TestStatistic", "KSampleT"}, VerifyTestAssumptions -> None]& /@ data;df = LocationEquivalenceTest[data[[1]], "DegreesOfFreedom"]Show[Plot[PDF[FRatioDistribution[df[[1]], df[[2]]], x], {x, 0, 5}, PlotRange -> {0, 1}], SmoothHistogram[kst, PlotStyle -> Orange]]DistributionFitTest[kst, FRatioDistribution[df[[1]], df[[2]]]]Under ![]() the complete block
the complete block ![]() and Friedman rank test statistics with t treatments and g blocks follows an FRatioDistribution[t-1,(g-1)(t-1)]:
and Friedman rank test statistics with t treatments and g blocks follows an FRatioDistribution[t-1,(g-1)(t-1)]:
data = RandomVariate[NormalDistribution[], {1000, 3, 200}];cbf = LocationEquivalenceTest[#, {"TestStatistic", "CompleteBlockF"}, VerifyTestAssumptions -> None]& /@ data;frt = LocationEquivalenceTest[#, {"TestStatistic", "FriedmanRank"}, VerifyTestAssumptions -> None]& /@ data;df = LocationEquivalenceTest[data[[1]], {"DegreesOfFreedom", "CompleteBlockF"}]Table[Show[Plot[PDF[FRatioDistribution[df[[1]], df[[2]]], x], {x, 0, 5}, PlotRange -> {0, 1}], SmoothHistogram[i, PlotStyle -> Orange]], {i, {cbf, frt}}]Table[DistributionFitTest[i, FRatioDistribution[df[[1]], df[[2]]]], {i, {cbf, frt}}]The Friedman statistic can be transformed to follow a ChiSquareDistribution[g-1]:
data = RandomVariate[NormalDistribution[], {1000, 3, 200}];frt = LocationEquivalenceTest[#, {"TestStatistic", "FriedmanRank"}, VerifyTestAssumptions -> None]& /@ data;df = LocationEquivalenceTest[data[[1]], {"DegreesOfFreedom", "FriedmanRank"}]chiFromF[F_, df1_, df2_] := (df1 (df1 + df2) F/df2 + df1 F)chisqrs = (chiFromF[#1, df[[1]], df[[2]]]&) /@ frt;Show[Plot[PDF[ChiSquareDistribution[df[[1]]], x], {x, 0, 10}, PlotRange -> {0, .5}], SmoothHistogram[chisqrs, PlotStyle -> Orange]]Compute a ![]() -value using ChiSquareDistribution:
-value using ChiSquareDistribution:
f = LocationEquivalenceTest[data[[1]], {"TestStatistic", "FriedmanRank"}]Probability[χ > chiFromF[f, df[[1]], df[[2]]], χChiSquareDistribution[df[[1]]]]This transformation is done automatically with Method set to "Asymptotic":
LocationEquivalenceTest[data[[1]], "FriedmanRank", Method -> "Asymptotic"]Under ![]() the Kruskal–Wallis test statistic asymptotically follows a ChiSquareDistribution[g-1] where g is the number of datasets:
the Kruskal–Wallis test statistic asymptotically follows a ChiSquareDistribution[g-1] where g is the number of datasets:
data = RandomVariate[NormalDistribution[], {1000, 3, 200}];kst = LocationEquivalenceTest[#, {"TestStatistic", "KruskalWallis"}, VerifyTestAssumptions -> None]& /@ data;Show[Plot[PDF[ChiSquareDistribution[2], x], {x, 0, 20}, PlotRange -> All], SmoothHistogram[kst, PlotStyle -> Orange]]DistributionFitTest[kst, ChiSquareDistribution[2]]By default, the test statistic is rescaled to follow an FRatioDistribution[g-1,n-g]:
fFromChi[χ_, n_, g_] := ((n - g)χ/(g - 1)(n - 1 - χ))DistributionFitTest[fFromChi[#, 600, 3]& /@ kst, FRatioDistribution[2, 597]]Conceptually, a comparison is made between the pooled and average individual variances:
μDifferent = {-3, 0, 3};
μSimilar = {0, 0, 0};σ = 1;Larger pooled variances indicate different means:
dDifferent = Table[RandomVariate[NormalDistribution[i, σ], 10 ^ 4], {i, μDifferent}];
dSimilar = Table[RandomVariate[NormalDistribution[i, σ], 10 ^ 4], {i, μSimilar}];{SmoothHistogram[Flatten[dDifferent]], SmoothHistogram[Flatten[dSimilar]]}The ratio of pooled to individual variances:
Variance[Flatten[dDifferent]] / Mean[Variance /@ dDifferent]Variance[Flatten[dSimilar]] / Mean[Variance /@ dSimilar]LocationEquivalenceTest effectively detects how far this ratio is from 1:
LocationEquivalenceTest[dDifferent]LocationEquivalenceTest[dSimilar]The ![]() and
and ![]() test statistics are used in LocationEquivalenceTest:
test statistics are used in LocationEquivalenceTest:
data = RandomVariate[NormalDistribution[], {3, 15}];ChiSquareStat[data_] := Block[{n = Length /@ data, g = Length[data], m = Mean /@ data, mbar = Mean[Flatten@data]},
(Total[n] - 1)((Underoverscript[∑, i = 1, g]n[[i]] (m[[i]] - mbar)^2/Underoverscript[∑, i = 1, g]Underoverscript[∑, j = 1, n[[i]]](data[[i, j]] - mbar)^2))//N
]fFromChi[χ_, n_, g_] := ((n - g)χ/(g - 1)(n - 1 - χ))fFromChi[ChiSquareStat[data], 3 * 15, 3]LocationEquivalenceTest[data, {"TestStatistic", "KSampleT"}]The Kruskal–Wallis statistic is rank-based:
ranks = Partition[Ordering[Ordering[Flatten@data]], 15];ChiSquareStat[ranks]LocationEquivalenceTest[data, {"TestStatistic", "KruskalWallis"}]For ![]() -sample
-sample ![]() and Kruskal–Wallis tests, the statistic can be computed using LinearModelFit:
and Kruskal–Wallis tests, the statistic can be computed using LinearModelFit:
n = 15;g = 3;data = RandomVariate[NormalDistribution[], {g, n}];designMat[n_, g_] := Block[{tot = Total[n]}, f[i_] := With[{nstart = If[i == 1, 1, Total[n[[1 ;; i - 1]]] + 1]}, ReplacePart[ConstantArray[0, tot], x_ /; nstart ≤ x < Total[n[[1 ;; i]]] + 1 -> 1]];Transpose[Join[{ConstantArray[1, tot]}, Table[f[i], {i, Range[g - 1]}]]]]loctst[dat_] := Block[{lm, MSR, MSE},
lm = LinearModelFit[{designMat[ConstantArray[n, g], g], dat}];
MSR = (Total[lm["ANOVATableSumsOfSquares"][[1 ;; g - 1]]]/g - 1);
MSE = (lm["ANOVATableSumsOfSquares"][[-2]]/Length[dat] - g);
MSR / MSE
]loctst[Flatten@data]LocationEquivalenceTest[data, {"TestStatistic", "KSampleT"}]The Kruskal–Wallis test is identical but uses ranks:
loctst[Ordering[Ordering[Flatten@data]]]fFromChi[χ_, n_, g_] := ((n - g)χ/(g - 1)(n - 1 - χ))fFromChi[LocationEquivalenceTest[data, {"TestStatistic", "KruskalWallis"}], n * g, g]Use LocationTest for two datasets:
BlockRandom[SeedRandom[10];data = RandomVariate[NormalDistribution[0, 1], {2, 100}]];LocationEquivalenceTest[data, "KSampleT"]LocationTest[data, Automatic, "T"]LocationTest can also test more complicated hypotheses:
LocationTest[data, 1.5, {"TestDataTable", "T"}, AlternativeHypothesis -> "Less"]The location equivalence test ignores the time stamps when the input is a TimeSeries:
ts1 = TemporalData[TimeSeries, {{{1.224578634529677, 0.47929635789978015, 0.6572781300178168,
0.21496048742669355, 0.7299608014554928, -0.2495111111278263, -1.3286551762002712,
0.552725018274874, 0.19272112205837066, 1.1809144012420882, -1.1671 ... 40938613662046, 1.052394590214582, 0.9345044123980388, 0.38537803109557855,
-0.48660931166089394, -0.71203560340161}}, {{0, 100, 1}}, 1, {"Continuous", 1},
{"Discrete", 1}, 1, {ValueDimensions -> 1, ResamplingMethod -> None}}, False, 10.1];ts2 = TemporalData[TimeSeries, {{{-1.2160757838495546, 0.5212591188357838, -0.0932747538180776,
-2.306367634798702, -2.5366722726947994, -0.7924813212437647, -2.65435901675047,
-1.1098678592653723, -0.7814091835518528, -1.9685555851254093, -0.0 ... 1001061264, -0.1887471329804458, -2.0547107874294928, -1.3896240275653011,
-0.5073077090484948, 0.13302942350391606}}, {{0, 100, 1}}, 1, {"Continuous", 1},
{"Discrete", 1}, 1, {ValueDimensions -> 1, ResamplingMethod -> None}}, False, 10.1];LocationEquivalenceTest[{ts1, ts2}]LocationEquivalenceTest[{ts1["Values"], ts2["Values"]}]The location equivalence test recognizes the path structure of a TemporalData:
td = TemporalData[Automatic, {{{0.6327956976018951, 0.49307164456668334, -0.11865815946302549,
-1.6346246228913748, -1.8053674367955113, -1.0171193599509663, -1.713536030590108,
-0.2441834126183119, 1.468610531363788, 2.5403283801476966, 0.862 ... 135928877112, 0.8411464201445826, 0.36308201253335104, -0.45737292436875443,
0.289078430933834, 0.12996366812717347}}, {{0, 100, 1}}, 4, {"Continuous", 4}, {"Discrete", 1},
1, {ValueDimensions -> 1, ResamplingMethod -> None}}, False, 10.1];LocationEquivalenceTest[td]LocationEquivalenceTest[td["ValueList"]]Possible Issues (3)
All of the tests require that the data has equal variances:
data1 = RandomVariate[NormalDistribution[0, 100], 100];
data2 = RandomVariate[NormalDistribution[], 100];
data3 = RandomVariate[NormalDistribution[1, 1], 100];LocationEquivalenceTest[{data1, data2, data3}, All]The ![]() -sample
-sample ![]() -test and complete block
-test and complete block ![]() test require that the data is normally distributed:
test require that the data is normally distributed:
data1 = RandomVariate[LaplaceDistribution[0, 1 / Sqrt[2]], 100];
data2 = RandomVariate[NormalDistribution[], 100];
data3 = RandomVariate[NormalDistribution[1, 1], 100];LocationEquivalenceTest[{data1, data2, data3}, {"CompleteBlockF", "KSampleT"}]The Kruskal–Wallis test or Friedman rank test should be used if the data is not normally distributed:
LocationEquivalenceTest[{data1, data2, data3}, "KruskalWallis"]The Friedman rank and complete block ![]() tests require equal sample sizes:
tests require equal sample sizes:
data1 = RandomVariate[NormalDistribution[], 100];
data2 = RandomVariate[NormalDistribution[], 100];
data3 = RandomVariate[NormalDistribution[], 15];LocationEquivalenceTest[{data1, data2, data3}, {"CompleteBlockF", "FriedmanRank"}]Neat Examples (1)
Compute the statistic when the null hypothesis ![]() is true:
is true:
data1 = RandomVariate[NormalDistribution[], {250, 100}];
data2 = RandomVariate[NormalDistribution[0, 2], {250, 100}];T1 = MapThread[LocationEquivalenceTest[{#1, #2}, "TestStatistic"]&, {data1, data2}];The test statistic given a particular alternative:
data3 = RandomVariate[NormalDistribution[1, 1], {250, 100}];T2 = MapThread[LocationEquivalenceTest[{#1, #2}, "TestStatistic"]&, {data1, data3}];Compare the distributions of the test statistics:
SmoothHistogram[{T1, T2}, Filling -> Axis, PlotLegends -> {"SubscriptBox[H, 0] is True", "SubscriptBox[H, 0] is False"}]Text
Wolfram Research (2010), LocationEquivalenceTest, Wolfram Language function, https://reference.wolfram.com/language/ref/LocationEquivalenceTest.html.
CMS
Wolfram Language. 2010. "LocationEquivalenceTest." Wolfram Language & System Documentation Center. Wolfram Research. https://reference.wolfram.com/language/ref/LocationEquivalenceTest.html.
APA
Wolfram Language. (2010). LocationEquivalenceTest. Wolfram Language & System Documentation Center. Retrieved from https://reference.wolfram.com/language/ref/LocationEquivalenceTest.html