AssessmentFunction
AssessmentFunction[key]
代表一个根据 key 评估答案是否正确的工具.
AssessmentFunction[key,method]
使用指明的答案比较方法.
AssessmentFunction[key,f]
使用函数 f 比较有键的答案.
AssessmentFunction[key,comp]
使用在 Association comp 对比中定义的客制化评估来进行评估.
AssessmentFunction[obj]
表示一个使用 CloudObject obj 进行评估的评估函数.
AssessmentFunction[{obj,id}]
评估 CloudObject obj 内的指定问题.
AssessmentFunction[…] [answer]
给出一个 AssessmentResultObject 代表 answer 的正确性.
更多信息和选项



- AssessmentFunction 通常用在 QuestionObject 中,定义如何评估问题的答案.
- key 接受下列形式:
-
ans 匹配模式 ans 的答案 {ans1,ans2,…} 答案为 ansi 的任意一个 {{a1,a2,…}} 答案为列表 {a1,a2,…} - 每个可能的答案 ansi 可有如下形式:
-
patt 匹配所有正确响应的答案 pattscore 给予的模式及响应分数 pattansspec 包括一个完整答案规约的 Association - 使用 pattscore 等价于 patt<"Score"score>.
- score 应有布尔值或数值. True 和正数值意味着正确答案,而 False、零或复制则表示不正确.
- patti 可为精确答案值或用于比较的 answer 的值相应的模式.
- 在 AssessmentFunction[{patt1,patt2,…}] 中,如果没有提供分数,则认为所有的 patti 都是正确的. 如果只有一个 patti 被设为 True 或正的分数,则所有其他 patti 被视为错误的答案.
- 完整答案规约 ansspec 接受以下键:
-
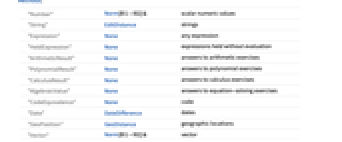
"Score" (required) 基于匹配答案的分数 "AnswerCorrect" 答案 ans 是否被判断为正确 "Category" 答案对应的种类,用于对问题分类 "Explanation" 提供给用户的文本 - AssessmentFunction[key,"method"] 中支持的答案比较方法包括以下 "method" 值,并使用相应的距离函数将答案和解与 Tolerance 相比较,其中 None 表示需要完全匹配. 方法也列在评估比较方法列表中.
-
"Number" Norm[#1-#2]& 标量数值 "String" EditDistance 字符串 "Expression" None 任意表达式 "HeldExpression" None 不进行计算的表达式 "ArithmeticResult" None 算术习题的答案 "PolynomialResult" None 多项式习题的答案 "CalculusResult" None 微积分习题的答案 "AlgebraicValue" None 解方程习题的答案 "CodeEquivalence" None 代码 "Date" DateDifference 日期 "GeoPosition" GeoDistance 地理位置 "Vector" Norm[#1-#2]& 向量 "Color" ColorDistance 颜色值 "Quantity" Norm[#1-#2]& 有幅值和单位的量 - 在 AssessmentFunction[key,comp]中,comp 是一个 Association. 可接受的键包括:
-
"ComparisonMethod" 命名比较方法 "method" "Comparator" 自定义函数,以比较提供的答案与 key 中的每个模式 "Selector" 为提供答案挑选匹配模式的函数 "ListAssessment" 规定评估所列答案的方法 "ScoreCombiner" 以元素方式合并 "Score" 值的函数 "AnswerCorrectCombiner" 以元素方式合并 "AnswerCorrect" 值的函数 - 函数 f 的 AssessmentFunction[key,f] 等价于 AssessmentFunction[key,<"Comparator"f>].
- 仅应提供 "Comparator" 和 "Selector" 中的一个. 使用 "Comparator"compf 可按顺序为键中的每个 ans 计算 compf[answer, patt] 并选择第一个 ans 给出 True. 常见的比较器包括 MatchQ、Greater、StringMatchQ 和 SameQ.
- 可以使用自定义比较器 f,它只接受用户的答案作为输入,而无需指定 key. 在这种情况下,Automatic 作为 key 被接受. 当 f[answer] 给出 True 时,评估被标记为正确. 当键不是 Automatic 时,f[answer, patti] 使用提交的 answer 和答案键中的每个 patti 计算;只要任何一个给出 True,评估就基于该 patti.
- 使用 "Selector"selectf 计算 selectf[{patt1,patt2,…},answer] 并返回与选择 ans 相应的 patt. 常见的选择器包括 SelectFirst、Composition[First,Nearest] 和 Composition[First,TakeLargestBy].
- 评估列表答案 AssessmentFunction[key,<…,"ListAssessment"method,…>][{elem1,elem2,…}] 时,method 支持以下值:
-
"SeparatelyScoreElements" 根据 key 分别评估答案的每个要素,并将结果合并 "AllElementsOrdered" 检查 answer 中的元素是否与 key 中的元素相匹配,且顺序匹配 "AllElementsOrderless" 检查 answer 中的元素是否与 key 中的元素相匹配,顺序不限 "WholeList" (default) 作为普通表达式进行评估,对整个列表 {elem1,elem2,…} 进行比较 - 对于 "SeparatelyScoredElements",key 中的 patt 应与答案中的各个元素相对应. 这样就可以为每个元素分配分数,如下所述. 对于所有其他 "ListAssessment" 方法,key 中的每个 patt 都应包含一个列表.
- 使用 "ListAssessment""SeparatelyScoreElements" 一次为一个元素评估列出的答案. 每个元素的 "Score" 和 "AnswerCorrect" 结果分别使用 "ScoreCombiner" 和 "AnswerCorrectCombiner" 函数. 只有在使用 "SeparatelyScoredElements" 时,才会应用 "ScoreCombiner" 和 "AnswerCorrectCombiner" 函数.
- AssessmentFunction 接受下列选项:
-
DistanceFunction Automatic 要使用的距离度量 Tolerance Automatic 当匹配答案时要接受的距离 MaxItems Infinity 在以元素方式进行评估时元素数量的限制 - AssessmentFunction[key] 等价于 AssessmentFunction[key,Automatic] 且可从 key 中推断出答案对比类型.
- 每个答案对比类型对应一个预定义的比较器或选择器函数. 通常情况下,若不存在比较类型的内置距离概念,则会使用 MatchQ 的 "Comparator".
- 若比较类型中不存在距离概念,则 AssessmentFunction 会使用 First@*Nearest 的 "Selector" 并接受 Tolerance 和 DistanceFunction 选项.
- 对于单独计分的元素,"AnswerCorrectCombiner" 应使用一个表示每个元素正确性的布尔值列表,并返回对答案整体正确性评估的单个布尔值. 默认值取决于比较方法. 最常见的默认值是 AllTrue[#,TrueQ]&.
- 对于单独计分的元素,"ScoreCombiner" 应使用一个表示每个元素分数的数值列表,并为答案返回一个总分. 默认值取决于比较方法. 最常见的默认值是 Total.
- 在分别对元素进行评分时,如果给出的元素数量大于 MaxItems 的值,则 AssessmentFunction 给出 Failure.
- Information 作用于 AssessmentFunction 并接受下列 prop 值:
-
"DefaultQuestionInterface" 键暗示的用户界面(如 "MultipleChoice", "ShortAnswer") "AnswerComparisonMethod" 值的期望类型(即,"Number"、"GeoPosition") "Key" 用于访问答案的键 - Information[AssessmentFunction[…],"Properties"] 提供了可用 prop 值的完整列表.
- AssessmentFunction[CloudObject[…]] 在指定的 CloudObject 中进行远程评估. 这样可以防止提供答案的用户对评估进行修改.
范例
打开所有单元关闭所有单元基本范例 (4)
范围 (28)
答案键 (8)
提供一个正确答案和相关评估作为 Association:
所有这些 AssessmentFunction 输入都是等效的:
通过为键中的每个项目指定一个 "Category",为分类问题创建一个 AssessmentFunction:
QuestionObject 中也提供了解释:
命名比较方法 (4)
或使用 Association:
当未指定比较方法时,AssessmentFunction 尝试自动确定适当的比较方法:
使用 Information 来检索所选的方法:
答案键值必须与比较方法一致. 使用答案键中的向量值进行 "Vector" 比较:
自定义比较方法 (5)
给出自定义比较器而不是命名方法,将答案键设置为 Automatic:
如果比较器函数应用于提交的答案时返回 True,则它是正确的:
或者,在 Association 中给出比较器:
创建一个带有自定义选择器的 AssessmentFunction 来确定键中的哪个值与提交的答案匹配:
为类似的问题创建两个评估函数,一个带有比较器,一个带有选择器:
选择器查看答案键中的所有值并选择最接近的值. 请注意,答案键中的值 3 对应的分数为 10:
保留值 (3)
使用 HoldPattern 指定 "HeldExpression" 比较方法来定义答案键值:
检查 Hold 所保持的表达式. 该表达式未求值:
数学比较方法如 "AlgebraicValue" 也接受保留值:
在评估期间,允许在 Hold 内进行适当的数学转换,例如基本算术:
"AlgebraicValue" 比较方法不允许像 SolveValues 这样的函数进行计算:
使用 HoldPattern 指定 "CodeEquivalence" 比较方法来定义答案键:
列表评估 (7)
通过指定 "ListAssessment""SeparatelyScoreElements" 为每个正确答案奖励点数:
创建一个设置为 "ListAssessment""AllElementsOrdered" 的 AssessmentFunction:
直接计算与 "AllElementsOrdered" 评估中等效的比较:
将其与默认的 "WholeList" 设置进行比较,该设置将提交的列表与整个答案进行比较. 请注意,选择的是 "Vector" 比较方法,而不是 "Number":
对于字符串列表,创建一个 "AllElementsOrdered" 评估函数. 请注意,推断出 "String" 比较方法:
为同一答案键创建一个"WholeList" 评估函数. 请注意,推断出列表的 "Expression" 比较方法:
每个元素的 "String" 比较都支持容差,例如允许大写差异:
"Expression" 比较不支持公差,答案被标记为不正确:
创建一个设置为 "ListAssessment""AllElementsOrderless" 的 AssessmentFunction:
比较方法(在本例中为 "CalculusResult")应用于每个元素,允许算术差异:
对同一答案键使用三种不同的 "ListAssessment" 设置. 请注意,对于 "SeparatelyScoreElements",答案键值不是列表:
所有三个设置都对元素进行独立比较. 使用“ "CalculusResult" 方法,数学上等价的值被标记为正确:
云部署 (1)
为佛罗里达州的地理位置创建 AssessmentFunction:
使用资源函数 QuestionDeploy 在云上部署评估函数:
部署的 AssessmentFunction 不包含答案键:
评估答案. 评估在已部署的 CloudObject 中安全进行:
选项 (6)
DistanceFunction (1)
MaxItems (4)
设置 "ListAssessment""SeparatelyScoreElements" 可计算答案中每个元素的评估值;这对某些比较器来说可能会比较慢:
限制可以访问 MaxItems 的元素数量:
创建一个评估函数,为每个元素分别打分. 请注意,键包含各元素可能值的分数:
查看完整结果. 请注意,"ElementInformation" 包含对每个元素的评估,并计算出完整答案的总 "Score" 和 "AnswerCorrect" 值:
创建一个评估函数,通过比较答案的每个元素和键的相应元素来评估所列答案:
应用 (3)
为多项式练习创建一个 QuestionObject:
属性和关系 (5)
使用 Information 提取关于 AssessmentFunction 的信息:
当使用 "ListAssessment""AllElementsOrdered" 时,答案键中的值是列表. 答案键列表中的每个元素都与提交的答案中的相应元素进行比较:
使用 "ListAssessment""AllElementsOrderless" 时会进行更多的比较:
当使用 "ListAssessment""SeparatelyScoreElements" 时,答案键是一个扁平的值列表,比较是在提交的答案的元素和键中的每个值之间进行的:
创建一个 "AllElementsOrderless" 评估函数,键值中包含重叠值:
文本
Wolfram Research (2020),AssessmentFunction,Wolfram 语言函数,https://reference.wolfram.com/language/ref/AssessmentFunction.html (更新于 2024 年).
CMS
Wolfram 语言. 2020. "AssessmentFunction." Wolfram 语言与系统参考资料中心. Wolfram Research. 最新版本 2024. https://reference.wolfram.com/language/ref/AssessmentFunction.html.
APA
Wolfram 语言. (2020). AssessmentFunction. Wolfram 语言与系统参考资料中心. 追溯自 https://reference.wolfram.com/language/ref/AssessmentFunction.html 年