

ClassifierMeasurements
ClassifierMeasurements[classifier,testset,prop]
classifier が testset について評価される際に,特性 prop に関連する評価測度を与える.
ClassifierMeasurements[classifier,testset]
任意の特性に適用することができる評価測度レポートを与える.
ClassifierMeasurements[data,…]
分類器の代りに分類 data を使う.
ClassifierMeasurements[…,{prop1,prop2,…}]
特性 prop1,prop2等を与える.
詳細とオプション










- 評価測度は,訓練目的(検定集合)で使われたのではないデータに対する分類器のパフォーマンスを決定するために使われる.
- 使用可能な評価測度には,分類法(正解率,尤度等),可視化(混同行列,ROC曲線等),特定の例(最悪の分類例等)がある.
- 分類器は,ClassifierFunction,あるいは"Class"デコーダを持つニューラルネット(NetGraph,NetChain等)でよい.
- 次は,ClassifierMeasurements[data,…]の分類 data の取り得る形式である.
-
{class1,class2,…} 分類器(人間,アルゴリズム等)からの分類 {dist1,dist2,…} 分類器で入手したクラス分布 {<class1p1,…>,<class1q1,…>,…} 分類器で入手した分類確率 - ClassifierMeasurements[…,opts]は,検定集合に適用されるときに分類器がオプション opts を使うように指定する.使用可能なオプションはClassifierFunctionで与えられる.
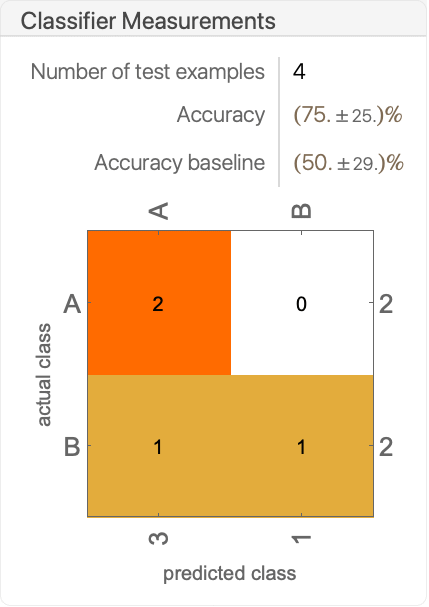
- ClassifierMeasurements[classifier,testset]は,以下のようなレポートパネルを表示するClassifierMeasurementsObject[…]を返す.
- ClassifierMeasurementsObject[…][prop]を使って特性 prop を入手することができる.繰り返し特性を検索する必要がある場合は,毎回ClassifierMeasurementsを使うよりこの方が効率的である.
- ClassifierMeasurementsObject[…][prop,opts]は,検定集合に適用されるときに分類器がオプション opts を使うように指定する.使用可能なオプションはClassifierFunctionで与えられる.
- ClassifierMeasurementsには,ClassifierFunction[…]のオプションに次を加えたものが使える.
-
Weights Automatic 検定集合例と関連した重み ComputeUncertainty False 尺度をその不確実性とともに与えるかどうか - ComputeUncertaintyTrueの設定のとき,数値評価測度値はAround[result,err]として与えられる.err は測定結果 result に関連付けられた(68%信頼区間に相当する)標準誤差を表す.
- 次はWeightsの可能な設定である.
-
Automatic 重み1とすべての検定例を関連付ける {w1,w2,…} 重み wiと i  番目の検定例を関連付ける
番目の検定例を関連付ける - 検定例の重みを1から2に変更することは,例を重複することに等しい.
- 重みは評価測度値とその不確定性に影響する.
- 次は,検定集合について分類能力に関連した単一の数値を返す特性である.
-
"Accuracy" 正しく分類された例の割合 "Accuracy"n トップ n 正解率 "AccuracyBaseline" 最頻クラスを予測する場合の正解率 "CohenKappa" コーエン(Cohen)のカッパ係数 "Error" 間違って分類された例の割合 "GeometricMeanProbability" 実クラス確率の幾何平均 "LogLikelihood" 検定集合が与えられた場合のモデルの対数尤度 "MeanCrossEntropy" 検定例についての平均クロスエントロピー "MeanDecisionUtility" 検定例についての平均効用 "Perplexity" 平均クロスエントロピーの指数 "RejectionRate" Indeterminateとして分類された例の割合 "ScottPi" スコット(Scott)のパイ係数 - Indeterminateと分類された検定例は,"Accuracy","Error","MeanCrossEntropy"のような,検定集合についての検定能力に関連した特性を計測する際には破棄される.
- 次は,混同行列に関連した特性である.
-
"ConfusionMatrix" クラス j として分類されたクラス i の例の数 cij "ConfusionMatrixPlot" 混同行列のプロット "ConfusionMatrixPlot"{c1,c2,…} クラス c1,c2等に限定された混同行列プロット "ConfusionMatrixPlot"n 最低の n のクラスの部分集合についての混同行列プロット "ConfusionFunction" 混同行列の値を与える関数 "TopConfusions" 最も混同されたクラスのペア "TopConfusions"n 最も混同されたクラスの n 組のペア - 次は,時間に関連した特性である.
-
"EvaluationTime" 検定集合の1つの例を分類するのにかかった時間 "BatchEvaluationTime" バッチの1つの例を分類するための限界時間 - 次は,各検定集合例に対して1つの値を返す特性である.
-
"DecisionUtilities" 各例についての効用関数の値 "Probabilities" 各例についての実クラス分類確率 "SHAPValues" 各例についてのシャープレイ加算特徴の説明 - "SHAPValues"は,さまざまな特徴を削除し次に合成した結果の予測を比較することで特徴の貢献度を評価する.オプションMissingValueSynthesisを使って欠測値を合成する方法が指定できる.SHAPの説明は,事前のクラスの訓練に関するオッズ比乗数として示される."SHAPValues"n を使ってSHAPの説明の数値推定に使われるサンプル数が制御できる.
- 次は,確率検量に関連した特性である.
-
"CalibrationCurve" ロジットスケールの確率検量線 "LinearCalibrationCurve" 線形スケールの確率検量線 "CalibrationData" 確率検量線データ - 次は,グラフィックスを返す特性である.
-
"AccuracyRejectionPlot" 棄却率の関数としての正解率のプロット "ICEPlots" 個別条件付き期待値(ICE)プロット "ProbabilityHistogram" 実際のクラス確率のヒストグラム "Report" 主な測定値をレポートするパネル "ROCCurve" 各クラスの受信者動作特性曲線 "SHAPPlots" 各クラスのシャープレイ加法機能の説明プロット - 次は,検定集合からの例を返す特性である.
-
"Examples" すべての検定例 "Examples"{i,j} クラス j として分類されたクラス i のすべての例 "BestClassifiedExamples" 実クラス確率が最高の例 "WorstClassifiedExamples" 実クラス確率が最低の例 "CorrectlyClassifiedExamples" 正しく分類された例 "MisclassifiedExamples" 誤って分類された例 "TruePositiveExamples" 各クラスの真陽性検定例 "FalsePositiveExamples" 各クラスの偽陽性検定例 "TrueNegativeExamples" 各クラスの真陰性検定例 "FalseNegativeExamples" 各クラスの偽陰性検定例 "IndeterminateExamples" Indeterminateとして分類された検定例 "LeastCertainExamples" 分布エントロピーが最高の例 "MostCertainExamples" 分布エントロピーが最低の例 - 例は inputiclassiの形で与えられる.ここで,classiは検定集合からの実際のクラスである.
- "WorstClassifiedExamples"や"MostCertainExamples"のような特性は10例まで出力する.ClassifierMeasurementsObject[…][propn]を使って出力数を n 例に指定することができる.
- 次は,各クラスに対して1つの値を返す特性である.
-
"AreaUnderROCCurve" 各クラスのROC曲線の下の面積 "ClassMeanCrossEntropy" 各クラスの平均クロスエントロピー "ClassRejectionRate" 各クラスの棄却率 "F1Score" 各クラスのF1スコア "FalseDiscoveryRate" 各クラス偽発見率 "FalseNegativeRate" 各クラスの偽陰性率 "FalsePositiveRate" 各クラスの偽陽性率 "MatthewsCorrelationCoefficient" 各クラスのマシュー相関係数 "NegativePredictiveValue" 各クラスについての陰性的中率 "Precision" 各クラスについての分類精度 "Recall" 各クラスの分類の再現率 "Specificity" 各クラスの特殊性 "TruePositiveNumber" 真陽性例の数 "FalsePositiveNumber" 偽陽性例の数 "TrueNegativeNumber" 真陰性例の数 "FalseNegativeNumber" 偽陰性例の数 - ClassifierMeasurementsObject[…][propclass]を使って指定されたクラスに関連付けられた値だけを返すことができる.
- ClassifierMeasurementsObject[…][prop<class1w1,class2w2,…>]を使って各クラスの値の重み付き平均を返すことができる.
- ClassifierMeasurementsObject[…][propf]を使って関数 f を返されたクラスの値に適用することができる(例:ClassifierMeasurementsObject[…][propMean]).
- "Precision"や"Recall"等の特性は可能な各「陽性クラス」に対して1つの値を与える.「陰性クラス」は陽性クラスではないすべてのクラスの和集合である.そのような特性については,ClassifierMeasurementsObject[…][propaverage]を使って,average が以下である場合に,可能なすべての陽性クラスの値を平均することができる.
-
"MacroAverage" 評価測度の平均を取る "WeightedMacroAverage" 各評価測度値に関連するクラス頻度で重みを付ける "MicroAverage" 全クラスの真陽性/真陰性等の例を連結して一意的な評価測度を与える - 次は,その他の特性である.
-
"ClassifierFunction" 測定されているClassifierFunction[…] "Properties" 使用可能な評価測度特性のリスト
例題
すべて開く すべて閉じるスコープ (7)
決定行列 (3)
混同行列と例の抽出 (1)
確率的評価測度 (1)
確率キャリブレーション (1)
オプション (6)
ClassPriors (1)
"Satellite"データ集合の訓練集合と検定集合をロードする:
分類器がClassPriorsの異なる値を持つ場合の混同集合を可視化する:
まずClassifierMeasurementsObjectを生成して,同じ操作を行う:
IndeterminateThreshold (1)
"Titanic"データ集合の訓練集合と検定集合をロードする:
分類器が別のIndeterminateThresholdの値を持つ場合に得られる混同行列を可視化する:
IndeterminateThresholdの異なる値について,検定集合についての分類器の正解率を測る:
TargetDevice (1)
TargetDeviceのさまざまな設定について,検定集合に対する分類器の正解率を測る:
UtilityFunction (1)
"Mushroom"データ集合の訓練集合と検定集合をロードする:
分類器が別のUtilityFunctionの値を持つ場合に得られる混同行列を可視化する:
まずClassifierMeasurementsObjectを生成し,同じ操作を行う:
ComputeUncertainty (1)
映画評の断片を"positive"か"negative"かに分類する分類器を訓練する:
検定集合を使ってClassifierMeasurements[…]オブジェクトを生成する:
アプリケーション (2)
フィッシャーの「アヤメ」のデータ集合について分類器を訓練し,4つの測定された特徴から アヤメの種 (setosa, versicolor, virginica) を予測する:
混同行列を生成し,分類器を使って検定集合の実際と予測上の分類を可視化する:
誤って"virginica"に分類されたクラス"versicolor"の例を抽出する:
MNISTデータ集合からのサンプルについて,分類器を訓練する:
MNIST検定集合についての,分類器のClassifierMeasurementsObjectを生成する:
各クラスのFスコアを計算し,どのクラスについて分類器を向上させるべきかを求める:
テキスト
Wolfram Research (2014), ClassifierMeasurements, Wolfram言語関数, https://reference.wolfram.com/language/ref/ClassifierMeasurements.html (2021年に更新).
CMS
Wolfram Language. 2014. "ClassifierMeasurements." Wolfram Language & System Documentation Center. Wolfram Research. Last Modified 2021. https://reference.wolfram.com/language/ref/ClassifierMeasurements.html.
APA
Wolfram Language. (2014). ClassifierMeasurements. Wolfram Language & System Documentation Center. Retrieved from https://reference.wolfram.com/language/ref/ClassifierMeasurements.html