

ClassifierMeasurements
ClassifierMeasurements[classifier,testset,prop]
给出当 classifier 在 testset 上运算时与属性 prop 关联的度量.
ClassifierMeasurements[classifier,testset]
生成一个可应用于任何属性的度量报告.
ClassifierMeasurements[data,…]
使用分类 data 而非分类器.
ClassifierMeasurements[…,{prop1,prop2,…}]
给出属性 prop1、prop2 等.
更多信息和选项










- 度量用于决定不用作训练目的(测试集)的数据分类器的性能.
- 可能的度量包括分类指标(准确性、似然性等)、可视化(混淆矩阵、受试者操作特征曲线(简称 ROC 曲线)等),或特定样例(如最糟的分类样例).
- 分类器可以是一个 ClassifierFunction 或一个有 "Class" 解码器的神经集(NetGraph、NetChain) 等.
- 在 ClassifierMeasurements[data,…] 中,分类 data 可有如下格式:
-
{class1,class2,…} 来自分类器的分类(人类、算法等) {dist1,dist2,…} 分类器获取的类别分布 {<class1p1,…>,<class1q1,…>,…} 分类器获取的分类概率 - ClassifierMeasurements[…,opts] 指定分类器在应用于测试集时应使用选项 opts. ClassifierFunction 给出了可能的选项.
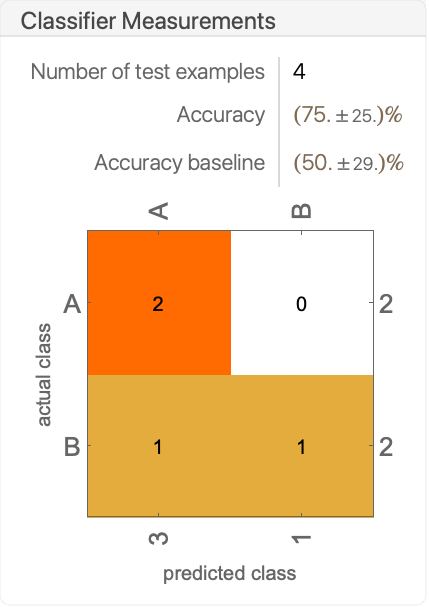
- ClassifierMeasurements[classifier,testset] 返回一个显示为一个报告面板的 ClassifierMeasurementsObject[…],如:
- ClassifierMeasurementsObject[…][prop] 可用于获取属性 prop. 当需要重复属性查询时,这会比每次都使用 ClassifierMeasurements 效率更高.
- ClassifierMeasurementsObject[…][prop,opts] 指定分类器在应用于测试集时应使用选项 opts. 这些选项可取代给到 ClassifierMeasurements 的原始选项.
- ClassifierMeasurements 与 ClassifierFunction[…] 的选项相同,额外选项如下所示:
-
Weights Automatic 与测试集的实例相关联的权重 ComputeUncertainty False 是否同时给出度量的统计不确定性 - 当设置为 ComputeUncertaintyTrue 时,将以 Around[result,err] 形式返回数值测量结果,其中 err 表示与测量 result 相关的标准偏差(对应于 68% 的置信区间).
- Weights 的可能设置包括:
-
Automatic 将权重 1 与所有测试实例关联起来 {w1,w2,…} 将权重 wi 与第 i  个测试实例关联起来
个测试实例关联起来 - 把测试实例的权重从 1 改为 2 等价于复制该实例.
- 权重影响度量和它们的不确定性.
- 返回与测试集上的分类能力相关的单个数值的属性包括:
-
"Accuracy" 正确分类实例的比例 "Accuracy"n 前 n 个准确率 "AccuracyBaseline" 如果预测最常见类的准确率 "CohenKappa" 科恩卡帕系数 "Error" 被错误分类实例的比例 "GeometricMeanProbability" 实际类别概率的几何平均 "LogLikelihood" 给出测试集的模型的对数似然 "MeanCrossEntropy" 测试实例的平均交叉熵 "MeanDecisionUtility" 测试实例的平均效用 "Perplexity" 平均交叉熵的指数 "RejectionRate" 被划分为 Indeterminate 的实例的比例 "ScottPi" Scott pi 系数 - 在测量与测试集上的分类能力相关的属性(如 "Accuracy"、"Error" 或 "MeanCrossEntropy")时,被分类为 Indeterminate 的实例将被丢弃.
- 与混淆矩阵相关的属性包括:
-
"ConfusionMatrix" 按 cij 类別 j 分类的类别 i 实例的計数 "ConfusionMatrixPlot" 混淆矩阵图形 "ConfusionMatrixPlot"{c1,c2,…} 限制于类别 c1、c2 等的混淆矩阵图 "ConfusionMatrixPlot"n 最差的 n 个类别组成的子集的混淆矩阵图 "ConfusionFunction" 给出混淆矩阵值的函数 "TopConfusions" 混淆程度最高的类别对 "TopConfusions"n 混淆程度最高的 n 个类别对 - 与用时相关的属性包括:
-
"EvaluationTime" 分类一个样例需要的时间 "BatchEvaluationTime" 当给定一批预测一个样例的边际时间 - 为测试集的每个实例返回一个值的属性包括:
-
"DecisionUtilities" 每个样例的效用函数的值 "Probabilities" 每个样例的实际类别分类概率 "SHAPValues" 每个样例的 Shapley 加性特征解释 - "SHAPValues" 通过比较将不同的特征集合删除,然后合成所得到的预测来评估特征的贡献. 选项 MissingValueSynthesis 可用于指定如何合成缺失的特征. SHAP 解释是以相对于 class training prior 的优势比乘数 (odds ratio multiplier) 给出的. 可通过 "SHAPValues"n 控制用于对 SHAP 解释进行数值估计的样本的数量.
- 与概率校准的属性包括:
-
"CalibrationCurve" Logit 标尺中的概率校准曲线 "LinearCalibrationCurve" 线性标尺中的概率校准曲线 "CalibrationData" 概率校准曲线数据 - 返回图形的属性包括:
-
"AccuracyRejectionPlot" 作为拒绝率函数的准确率的绘图 "ICEPlots" 个体条件期望 (ICE) 图 "ProbabilityHistogram" 实际类别概率的直方图 "Report" 报告主要度量的面板 "ROCCurve" 每个类别的接收者操作特征曲线 "SHAPPlots" 每个类别的 Shapley 加性特征解释图 - 从测试集返回实例的属性包括:
-
"Examples" 所有测试实例 "Examples"{i,j} 被划分为 j 类的所有 i 类实例 "BestClassifiedExamples" 实际类别概率最高的实例 "WorstClassifiedExamples" 实际类别概率最低的实例 "CorrectlyClassifiedExamples" 被正确分类的实例 "MisclassifiedExamples" 被错误分类的实例 "TruePositiveExamples" 每个类别的真正类测试实例 "FalsePositiveExamples" 每个类别的假正类测试实例 "TrueNegativeExamples" 每个类别的真负类测试实例 "FalseNegativeExamples" 每个类别的假负类测试实例 "IndeterminateExamples" 被划分为 Indeterminate 的测试实例 "LeastCertainExamples" 分布熵最高的实例 "MostCertainExamples" 分布熵最低的实例 - 以 inputiclassi 形式给出实例,其中 classi 是测试集中实例的实际类别.
- 如 "WorstClassifiedExamples" 或 "MostCertainExamples" 这样的属性最多输出 10 个实例. ClassifierMeasurementsObject[…][propn] 可用来输出 n 个实例.
- 为每个类返回一个测量值的属性包括:
-
"AreaUnderROCCurve" 每个类别的 ROC 曲线下的面积 "ClassMeanCrossEntropy" 每个类别的平均交叉熵 "ClassRejectionRate" 每个类别的拒绝率 "F1Score" 每个类别的 F1 值 "FalseDiscoveryRate" 每个类别的错误发现率 "FalseNegativeRate" 每个类别的假负类率 "FalsePositiveRate" 每个类别的假正类率 "MatthewsCorrelationCoefficient" 每个类别的 Matthews 相关系数 "NegativePredictiveValue" 每个类别的负例命中率 "Precision" 每个类别的分类的精确度 "Recall" 每个类别的分类的召回率 "Specificity" 每个类别的特异性 "TruePositiveNumber" 真正类实例的数量 "FalsePositiveNumber" 假正类实例的数量 "TrueNegativeNumber" 真负类实例的数量 "FalseNegativeNumber" 假负类实例的数量 - ClassifierMeasurementsObject[…][propclass] 可用来仅返回与指定类别关联的测量值.
- ClassifierMeasurementsObject[…][prop<class1w1,class2w2,…>] 可用来返回每个类别测量值的加权平均值.
- ClassifierMeasurementsObject[…][propf] 可用来对返回的类别测量值应用函数 f(如 ClassifierMeasurementsObject[…][propMean]).
- 如 "Precision" 或 "Recall" 这样的属性为每个可能的“正类”给出一个测量值. “负类”是所有非“正类”的类的组合. 对于这样的属性,我们可以用 ClassifierMeasurementsObject[…][propaverage] 求所有可能的正类的测量值的平均值,其中 average 可以是:
-
"MacroAverage" 所有测量值的统一平均值 "WeightedMacroAverage" 根据相关的类的频次对每个测量值进行加权 "MicroAverage" 合并真正类/真负类等实例,给出唯一的测量值 - 其他属性包括:
-
"ClassifierFunction" 当前被测量的 ClassifierFunction[…] "Properties" 可用测量属性列表
范例
打开所有单元 关闭所有单元基本范例 (4)
范围 (7)
决定指标 (3)
混淆矩阵和样例提取 (1)
概率指标 (1)
概率校准 (1)
选项 (6)
ClassPriors (1)
当分类器具有 ClassPriors 的不同值时,可视化获得的混淆矩阵:
通过首先生成 ClassifierMeasurementsObject,执行相同的操作:
IndeterminateThreshold (1)
当分类器具有 IndeterminateThreshold 的不同值时,可视化获得的混淆矩阵:
对于 IndeterminateThreshold 的不同值,度量测试集上分类器的准确度:
TargetDevice (1)
对 TargetDevice 不同设置的测试集度量分类器的精确度:
UtilityFunction (1)
当分类器具有 UtilityFunction 的不同值时,可视化获得的混淆矩阵:
通过首先生成 ClassifierMeasurementsObject,执行相同的操作:
"Uncertainty" (1)
训练一个分类器,把影评片段分类为 "positive" 或 "negative":
用测试集生成一个 ClassifierMeasurements[…] 对象:
应用 (2)
对于费雪鸢尾花卉数据集,训练一个分类器,使其从四个测得特征来预测鸢尾花卉的种类(山鸢尾、变色鸢尾和维吉尼亚鸢尾):
生成一个混淆矩阵,对试验数据的实际分类和利用分类器的预测分类进行可视化:
对错误归类为 "virginica" 的类别 "versicolor" 的实例进行提取:
生成 MNIST 测试集上分类器的 ClassifierMeasurementsObject:
文本
Wolfram Research (2014),ClassifierMeasurements,Wolfram 语言函数,https://reference.wolfram.com/language/ref/ClassifierMeasurements.html (更新于 2021 年).
CMS
Wolfram 语言. 2014. "ClassifierMeasurements." Wolfram 语言与系统参考资料中心. Wolfram Research. 最新版本 2021. https://reference.wolfram.com/language/ref/ClassifierMeasurements.html.
APA
Wolfram 语言. (2014). ClassifierMeasurements. Wolfram 语言与系统参考资料中心. 追溯自 https://reference.wolfram.com/language/ref/ClassifierMeasurements.html 年