"LatentSemanticAnalysis" (Machine Learning Method)
"LatentSemanticAnalysis" (Machine Learning Method)
- Method for DimensionReduction, DimensionReduce, FeatureSpacePlot and FeatureSpacePlot3D.
- Maps the data into a lower-dimensional space using the latent semantic analysis method.
Details & Suboptions
- "LatentSemanticAnalysis" is a linear dimensionality reduction method. The method projects input data in a lower-dimensional space that attempts to preserve the semantic association between data points.
- "LatentSemanticAnalysis" works for datasets that have a large number of features or large number of examples, and works particularly well for sparse datasets (for which most values are zeros). "LatentSemanticAnalysis" is typically used to reduce the dimension of a term-document matrix (term counts in documents).
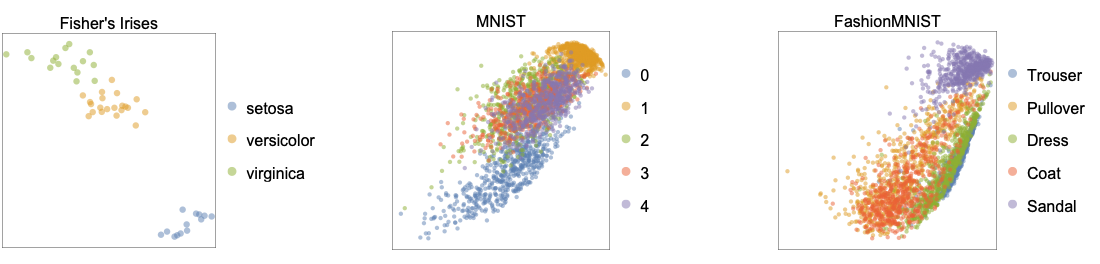
- The following plots show the results of the "LatentSemanticAnalysis" method applied to benchmarking datasets including Fisher's Irises, MNIST and FashionMNIST:
- "LatentSemanticAnalysis" is equivalent to "Linear" and "PrincipalComponentsAnalysis" methods, with the exception that the data is not centered.
- The method is widely used in informational retrieval to create search engines. The method is also used in natural language processing for tasks such as text classification and topic modeling.
Examples
open all close allBasic Examples (1)
Train a linear dimensionality reduction using the "LatentSemanticAnalysis" method from a list of vectors:
reducer = DimensionReduction[{{1, 2, 3}, {2, 3, 5}, {3, 5, 8}, {4, 5, 8.5}}, 2, Method -> "LatentSemanticAnalysis"]Use the trained reducer on new vectors:
reducer[{{6, 7, 14}, {5, 6, 11}, {1, 3, 9}}]Scope (1)
Dataset Visualization (1)
Load the Fisher Iris dataset from ExampleData:
iris = ExampleData[{"MachineLearning", "FisherIris"}, "Data"];RandomSample[iris, 5]Generate a reducer function using "LatentSemanticAnalysis" with the features of each example:
diris = DimensionReduction[iris[[All, 1]], 2, Method -> "LatentSemanticAnalysis"]Group the examples by their species:
byspecies = GroupBy[iris, Last -> First];Reduce the dimension of the features:
byspecies = diris /@ byspecies;Visualize the reduced dataset:
ListPlot[Values[byspecies], PlotLegends -> Keys[byspecies]]Applications (1)
Text Analysis (1)
txt = ExampleData[{"Text", "DonQuixoteIEnglish"}];Split the text into sentences:
sent = TextSentences[txt];Train a reducer on these sentences:
dr = DimensionReduction[sent, 20, Method -> "LatentSemanticAnalysis"]Train a nearest function on the embedding of sentences:
nf = Nearest[dr[sent] -> "Index"]Use the function to find the nearest sentence to a query in the reduced semantic space:
query = "The knight";
Part[sent, First@nf[dr[query]]]