"LinearRegression" (Machine Learning Method)
- Method for Predict.
- Predict values using a linear combination of features.
Details & Suboptions
- The linear regression predicts the numerical output y using a linear combination of numerical features
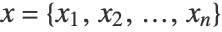 . The conditional probability
. The conditional probability 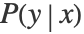 is modeled according to
is modeled according to 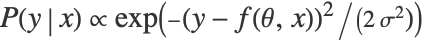 , with
, with 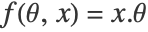 .
. - The estimation of the parameter vector θ is done by minimizing the loss function
![1/2sum_(i=1)^m(y_i-f(theta,x_i))^2+lambda_1sum_(i=1)^nTemplateBox[{{theta, _, i}}, Abs]+(lambda_2)/2 sum_(i=1)^ntheta_i^2](Files/LinearRegression.en/5.png "1/2sum_(i=1)^m(y_i-f(theta,x_i))^2+lambda_1sum_(i=1)^nTemplateBox[{{theta, _, i}}, Abs]+(lambda_2)/2 sum_(i=1)^ntheta_i^2") , where m is the number of examples and n is the number of numerical features.
, where m is the number of examples and n is the number of numerical features. - The following suboptions can be given:
-
"L1Regularization" 0 value of 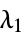 in the loss function
in the loss function"L2Regularization" Automatic value of 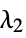 iin the loss function
iin the loss function"OptimizationMethod" Automatic what optimization method to use - Possible settings for the "OptimizationMethod" option include:
-
"NormalEquation" linear algebra method "StochasticGradientDescent" stochastic gradient method "OrthantWiseQuasiNewton" orthant-wise quasi-Newton method - For this method, Information[PredictorFunction[…],"Function"] gives a simple expression to compute the predicted value from the features.
Examples
open all close allBasic Examples (2)
Train a predictor on labeled examples:
p = Predict[{1, 2, 3, 4} -> {.3, .4, .6, 9}, Method -> "LinearRegression"]Look at the Information:
Information[p]p[1.3]Generate two-dimensional data:
data = Table[x -> x + RandomVariate[NormalDistribution[]], {x, RandomReal[{-5, 5}, 40]}];
ListPlot[List@@@data]Train a predictor function on it:
p = Predict[data, Method -> "LinearRegression"]Compare the data with the predicted values and look at the standard deviation:
Show[Plot[{
p[x],
p[x] + StandardDeviation[p[x, "Distribution"]], p[x] - StandardDeviation[p[x, "Distribution"]]},
{x, -2, 6},
PlotStyle -> {Blue, Gray, Gray},
Filling -> {2 -> {3}},
Exclusions -> False,
PerformanceGoal -> "Speed", PlotLegends -> {"Prediction", "Confidence Interval"}
],
ListPlot[List@@@data, PlotStyle -> Red, PlotLegends -> {"Data"}]
]Options (5)
"L1Regularization" (2)
Use the "L1Regularization" option to train a predictor:
p = Predict[{1, 2, 3, 4} -> {.3, .4, .6, 9}, Method -> {"LinearRegression", "L1Regularization" -> 1}]Generate a training set and visualize it:
trainingset = Flatten[Table[{x, y} -> x + RandomReal[1], {x, RandomReal[{-5, 5}, 20]}, {y, RandomReal[{-5, 5}, 20]}], 1];
ListPointPlot3D[Flatten /@ List@@@trainingset]Train two predictors by using different values of the "L1Regularization" option:
p0 = Predict[trainingset, Method -> {"LinearRegression", "L1Regularization" -> 0}]p7 = Predict[trainingset, Method -> {"LinearRegression", "L1Regularization" -> 7}]Look at the predictor function to see how the larger L1 regularization has forced one parameter to be zero:
Information[p0, "Function"]Information[p7, "Function"]"L2Regularization" (2)
Use the "L2Regularization" option to train a predictor:
p = Predict[{1, 2, 3, 4} -> {.3, .4, .6, 9}, Method -> {"LinearRegression", "L2Regularization" -> 1}]Generate a training set and visualize it:
trainingset = Table[x -> x + RandomReal[{-3, 3}], {x, RandomReal[{-5, 5}, 20]}];
ListPlot[List@@@trainingset]Train two predictors by using different values of the "L2Regularization" option:
p0 = Predict[trainingset, Method -> {"LinearRegression", "L2Regularization" -> 0}]p5 = Predict[trainingset, Method -> {"LinearRegression", "L2Regularization" -> 5}]Look at the predictor functions to see how the L2 regularization has reduced the norm of the parameter vector:
{f1, f2} = Information[#, "Function"]& /@ {p0, p5}{theta1, theta2} = Most[Cases[#, _ ? NumericQ, Infinity]]& /@ {f1, f2};
Norm /@ {theta1, theta2}"OptimizationMethod" (1)
Generate a large training set:
n = 20000;
dim = 20;
trainingset = RandomReal[{-5, 5}, {n, dim}] -> RandomReal[1, n];Train predictors with different optimization methods and compare their training times:
AbsoluteTiming[p1 = Predict[trainingset, Method -> {"LinearRegression", "OptimizationMethod" -> "NormalEquation"}];]AbsoluteTiming[p2 = Predict[trainingset, Method -> {"LinearRegression", "OptimizationMethod" -> "OrthantWiseQuasiNewton"}];]