

KendallTauTest
KendallTauTest[v1,v2]
ベクトル v1とベクトル v2が独立かどうかの検定を行う.
KendallTauTest[m1,m2]
行列 m1と行列 m2が独立かどうかの検定を行う.
KendallTauTest[…,"property"]
"property"の値を返す.
詳細とオプション


- KendallTauTestは,v1と v2に対して,ベクトルが独立であるという帰無仮説
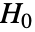 と,そうではないという対立仮説
と,そうではないという対立仮説 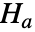 で仮説検定を行う.
で仮説検定を行う. - デフォルトで,確率値つまり
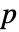 値が返される.
値が返される. - 小さい
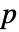 値は
値は 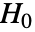 が真である可能性が低いことを示す.
が真である可能性が低いことを示す. - 引数 v1と v2 は任意の同じ長さの実ベクトルあるいは実行列でよい.
- KendallTauTestはKendallTau[v1,v2]で計算されたケンドール(Kendall)の順位相関
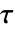 に基づいている.
に基づいている. - 行列の検定の際,検定統計は内部の標準化された空間符号と順位の比率に基づき,ChiSquareDistribution[r*s]に漸近的に従う.ただし,r および s はそれぞれ m1および m2の次元である.
- KendallTauTest[v1,v2,"HypothesisTestData"]はHypothesisTestDataオブジェクト htd を返す.このオブジェクトは,htd["property"] の形を使った追加的な検定結果と特性の抽出に使うことができる.
- KendallTauTest[v1,v2,"property"]を使って"property"の値を直接与えることができる.
- 検定結果のレポートに関連する特性
-
"DegreesOfFreedom" 検定に使われる自由度 "PValue" 検定の 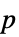 値
値"PValueTable" 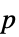 値を含むフォーマットされた表
値を含むフォーマットされた表"ShortTestConclusion" 検定結果の短い記述 "TestConclusion" 検定結果の記述 "TestData" 検定統計量と 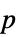 値のリスト
値のリスト"TestDataTable" 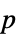 値と検定統計量のフォーマットされた表
値と検定統計量のフォーマットされた表"TestStatistic" 検定統計量 "TestStatisticTable" 検定統計量のフォーマットされた表 - 使用可能なオプション
-
AlternativeHypothesis "Unequal" 対立仮説のための不等式 MaxIterations Automatic 多変量検定のための最大反復回数 Method Automatic 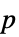 値の計算に使うメソッド
値の計算に使うメソッドSignificanceLevel 0.05 診断とレポートのための切捨て - 独立性の検定については,
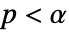 のときにのみ
のときにのみ 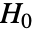 が拒絶されるような切捨て
が拒絶されるような切捨て 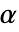 が選ばれる."TestConclusion"特性と"ShortTestConclusion"特性に使われる
が選ばれる."TestConclusion"特性と"ShortTestConclusion"特性に使われる 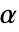 の値はSignificanceLevelオプションで制御される.デフォルトで,
の値はSignificanceLevelオプションで制御される.デフォルトで,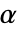 は0.05に設定されている.
は0.05に設定されている.
例題
すべて開く すべて閉じるスコープ (8)
検定 (5)
繰り返し特性を抽出するためにHypothesisTestDataオブジェクトを作る:
HypothesisTestDataオブジェクトからいくつかの特性を抽出する:
オプション (9)
AlternativeHypothesis (3)
Method (4)
特性と関係 (5)
ベクトル間の比較の際,検定統計量はKendallTauとして計算される:
行列の比較の際は,検定統計量はChiSquareDistribution[r*s]に従う:
行列の比較の際は,検定統計量はアフィン変換の下で不変である:
IndependenceTestを使って独立性の適切な検定を選ぶことができる:
KendallTauTestは使用できる検定の一つである:
KendallTauTestは単調従属しか検出しない:
HoeffdingDTestを使ってより多様な従属構造を検出することができる:
テキスト
Wolfram Research (2012), KendallTauTest, Wolfram言語関数, https://reference.wolfram.com/language/ref/KendallTauTest.html.
CMS
Wolfram Language. 2012. "KendallTauTest." Wolfram Language & System Documentation Center. Wolfram Research. https://reference.wolfram.com/language/ref/KendallTauTest.html.
APA
Wolfram Language. (2012). KendallTauTest. Wolfram Language & System Documentation Center. Retrieved from https://reference.wolfram.com/language/ref/KendallTauTest.html