

LogRankTest
LogRankTest[{data1,data2,…}]
使用对数秩类型检验,在 datai 中测试等风险率.
LogRankTest[{data1,data2,…},wspec]
执行权值为 wspec 的加权对数秩检验.
LogRankTest[{data1,…},wspec,"property"]
返回 "property" 的值.
更多信息和选项



- LogRankTest 对 datai 执行假设检验,其中零假设
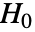 为总体的真实风险率等于
为总体的真实风险率等于 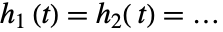 (对于全部
(对于全部 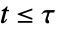 ),而备择假设
),而备择假设 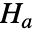 :对于某些
:对于某些 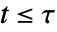 的值,至少一个
的值,至少一个 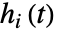 是不同的.
是不同的. - 数字
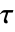 通常是 datai 中的最大的事件时间.
通常是 datai 中的最大的事件时间. - 默认情况下,返回概率值或者
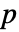 值.
值. - 较小的
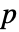 值表明
值表明 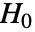 不可能是真的.
不可能是真的. - datai 必须是单变量 {x1,x2,…}.
- datai 可以是 SparseArray 或者 EventData 对象.
- LogRankTest 基于
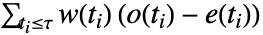 ,其中
,其中 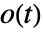 、
、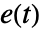 和
和 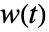 分别是观测到的事件数目,基于共用的样本的期望事件数目和某些权值.
分别是观测到的事件数目,基于共用的样本的期望事件数目和某些权值. - 对于已命名权值方法,时间
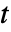 处的权值
处的权值 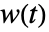 通常基于风险
通常基于风险 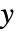 处的数目,事件数
处的数目,事件数 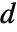 ,共用样本的乘积极限估值
,共用样本的乘积极限估值 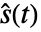 ,或者共用样本的相似估值
,或者共用样本的相似估值 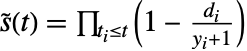 .
. - 可以给出下列权值指定 wspec:
-
ρ Fleming–Harrington 权值,其中 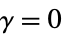
{ρ,γ} 完全指定的 Fleming–Harrington 权值 "name" 使用已命名权值方法 - ρ 和 γ 的值可以是任意非负数值.
- 指定 ρ 和 γ 产生形如
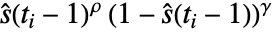 的 Fleming–Harrington 权值.
的 Fleming–Harrington 权值. - 可能的已命名权值指定包括:
-
"AndersenPeto" s^~(t_(i))/(y_(i)+1)")
"Equal" 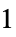
"Gehan" 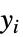
"Peto" 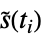
"TaroneWare" 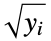
- 对于区间删失数据,使用 Zhao–Zhao–Sun–Kim 广义对数秩检验.
- LogRankTest[{data1,…},wspec,"HypothesisTestData"] 返回 HypothesisTestData 对象 htd,它可以用于使用格式 htd["property"] 提取额外检验结果和属性.
- LogRankTest[{data1,…},wspec,"property"] 可用于直接给出 "property" 的值.
- 与检验结果报告相关的属性包括:
-
"DegreesOfFreedom" 用于检验的自由度 "EventTimes" 用于检验的时间点列表 "EventWeights" 用于每个事件时间的权值列表 "PValue" 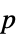 值列表
值列表"PValueTable" 由 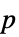 值组成的格式化表格
值组成的格式化表格"ShortTestConclusion" 检验结论的简短描述 "TestConclusion" 检验结论的描述 "TestData" 检验统计量和 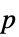 值组成的对的列表
值组成的对的列表"TestDataTable" 由 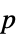 值和检验统计量组成的格式化表格
值和检验统计量组成的格式化表格"TestStatistic" 检验统计量的列表 "TestStatisticTable" 检验统计量的格式化表格 - 可以给出下列选项:
-
Method Automatic 用于计算 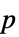 值的方法
值的方法SignificanceLevel 0.05 诊断和报告的截止
范例
打开所有单元 关闭所有单元基本范例 (4)
创建 HypothesisTestData 对象,以进行重复属性提取:
范围 (11)
检验 (7)
使用完全指定的 Fleming–Harrington 类型权值:
从 HypothesisTestData 对象提取某些属性:
选项 (4)
属性和关系 (7)
默认情况下,在 ![]() 下,假定检验统计量服从 ChiSquareDistribution:
下,假定检验统计量服从 ChiSquareDistribution:
Fleming–Harrington 参数适合精细控制,而不是加权处理:
MannWhitneyTest 可用于没有双样本删失的情况:
Kruskal–Wallis 检验可用于不出现多于两个样本的删失的情况:
使用 SurvivalModelFit 估计生存概率:
在出现协方差时,使用 CoxModelFit 估计生存概率:
对数秩检验可以识别 TemporalData 的路径结构:
文本
Wolfram Research (2012),LogRankTest,Wolfram 语言函数,https://reference.wolfram.com/language/ref/LogRankTest.html.
CMS
Wolfram 语言. 2012. "LogRankTest." Wolfram 语言与系统参考资料中心. Wolfram Research. https://reference.wolfram.com/language/ref/LogRankTest.html.
APA
Wolfram 语言. (2012). LogRankTest. Wolfram 语言与系统参考资料中心. 追溯自 https://reference.wolfram.com/language/ref/LogRankTest.html 年