PearsonChiSquareTest
PearsonChiSquareTest[data]
使用皮尔森 ![]() (卡方)检验法判断 data 是否服从正态分布.
(卡方)检验法判断 data 是否服从正态分布.
PearsonChiSquareTest[data,dist]
使用皮尔森 ![]() 检验法判断 data 是否服从 dist 分布.
检验法判断 data 是否服从 dist 分布.
PearsonChiSquareTest[data,dist,"property"]
返回 "property" 的值.
更多信息和选项


- PearsonChiSquareTest 执行具有零假设
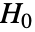 的皮尔森
的皮尔森 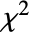 拟合优度检验,其中 data 来自于具有 dist 分布的总体,而备择假设
拟合优度检验,其中 data 来自于具有 dist 分布的总体,而备择假设 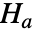 则不是.
则不是. - 默认情况下,返回一个概率值或者
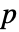 值.
值. - 一个较小的
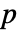 值表明 data 不可能服从 dist.
值表明 data 不可能服从 dist. - dist 可以是任意具有数值和符号参数或者数据集的符号分布.
- data 可以是单变量 {x1,x2,…} 或者多变量 {{x1,y1,…},{x2,y2,…},…}.
- 皮尔森
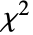 检验实际上将 data 的直方图与基于 dist 得到的理论直方图相比较. 选择的柱在 dist 中具有相同的概率. »
检验实际上将 data 的直方图与基于 dist 得到的理论直方图相比较. 选择的柱在 dist 中具有相同的概率. » - 对于单变量数据,检验统计量由
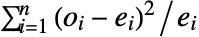 给出,其中
给出,其中 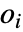 和
和 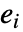 分别是第
分别是第 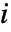
 个直方图柱的观测和期望数目.
个直方图柱的观测和期望数目. - 对于多变量检验,使用单变量边缘
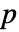 值的总和,并假设遵循
值的总和,并假设遵循 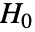 下的 UniformSumDistribution.
下的 UniformSumDistribution. - PearsonChiSquareTest[data,dist,"HypothesisTestData"] 返回一个 HypothesisTestData 对象 htd,通过使用 htd["property"] 的形式,它可以用来提取额外的检验结果和属性.
- PearsonChiSquareTest[data,dist,"property"] 可以用来直接给出 "property" 的值.
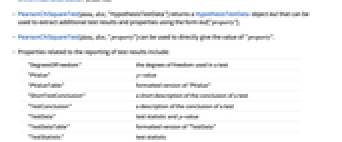
- 与检验报告相关的属性包括:
-
"DegreesOfFreedom" 检验中所使用的自由度 "PValue" 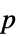 值
值"PValueTable" "PValue" 的格式化版本 "ShortTestConclusion" 一个检验结论的简短描述 "TestConclusion" 一个检验结论的描述 "TestData" 检验统计量和 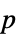 值
值"TestDataTable" "TestData" 的格式化版本 "TestStatistic" 检验统计量 "TestStatisticTable" 格式化的 "TestStatistic" - 下列属性与所执行的检验类型无关.
- 与数据分布相关的属性包括:
-
"FittedDistribution" 数据的拟合分布 "FittedDistributionParameters" 数据的分布参数 - 可以给出下列选项:
-
Method Automatic 计算 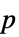 值所用的方法
值所用的方法SignificanceLevel 0.05 诊断和报告的分界点 - 对于一个拟合优度检验,选择一个临界值
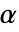 ,以使得只有当
,以使得只有当 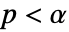 时,否定
时,否定 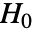 . 用于 "TestConclusion" 和 "ShortTestConclusion" 属性的
. 用于 "TestConclusion" 和 "ShortTestConclusion" 属性的 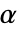 值由 SignificanceLevel 选项控制. 默认情况下,
值由 SignificanceLevel 选项控制. 默认情况下,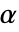 设为 0.05.
设为 0.05. - 在设置 Method->"MonteCarlo" 下,在
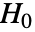 下使用拟合分布,生成
下使用拟合分布,生成 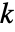 个与输入
个与输入 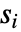 具有相同长度的数据集. 来自 PearsonChiSquareTest[si,dist,"TestStatistic"] 的 EmpiricalDistribution 用于估计
具有相同长度的数据集. 来自 PearsonChiSquareTest[si,dist,"TestStatistic"] 的 EmpiricalDistribution 用于估计 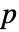 值.
值.
范例
打开所有单元关闭所有单元范围 (9)
检验 (6)
创建一个 HypothesisTestData 对象以进行重复属性提取:
选项 (3)
应用 (2)
当基本分布为 UniformDistribution[{-4,4}],检验大小为0.05,样本数为12时,估计皮尔森 ![]() 检验的功率:
检验的功率:
记录一个城市30天的汽车意外数目. 市议会正计划在这个城市降低车速限制,并希望作一个以事故率为基准的模型,以便日后比较:
经常用 PoissonDistribution 模拟计数数据:
属性和关系 (10)
默认情况下,单变量数据与一个 NormalDistribution 进行比较:
默认情况下,多变量数据与一个 MultinormalDistribution 进行比较:
PearsonChiSquareTest 有效的比较观察的和期望的直方图:
如果参数未知,PearsonChiSquareTest 校正自由度:
在 ![]() 下,皮尔森
下,皮尔森 ![]() 统计量近似服从一个 ChiSquareDistribution:
统计量近似服从一个 ChiSquareDistribution:
当输入为 TimeSeries 时,皮尔森 ![]() 检验只能用于数值:
检验只能用于数值:
文本
Wolfram Research (2010),PearsonChiSquareTest,Wolfram 语言函数,https://reference.wolfram.com/language/ref/PearsonChiSquareTest.html.
CMS
Wolfram 语言. 2010. "PearsonChiSquareTest." Wolfram 语言与系统参考资料中心. Wolfram Research. https://reference.wolfram.com/language/ref/PearsonChiSquareTest.html.
APA
Wolfram 语言. (2010). PearsonChiSquareTest. Wolfram 语言与系统参考资料中心. 追溯自 https://reference.wolfram.com/language/ref/PearsonChiSquareTest.html 年