SmoothKernelDistribution
SmoothKernelDistribution[{x1,x2,…}]
データ値 xiに基づいた平滑化カーネル分布を表す.
SmoothKernelDistribution[{{x1,y1,…},{x2,y2,…},…}]
データ値{xi,yi,…}に基づいた多変量平滑化カーネル分布を表す.
SmoothKernelDistribution[…,bw]
帯域幅 bw の平滑化カーネル分布を表す.
SmoothKernelDistribution[…,bw,ker]
帯域幅 bw,平滑化カーネル ker の平滑化カーネル分布を表す.
詳細とオプション




- SmoothKernelDistributionは他の任意の確率分布とも同じように使えるDataDistributionオブジェクトを返す.
- SmoothKernelDistributionの値
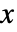 についての確率密度関数は,平滑化カーネル
についての確率密度関数は,平滑化カーネル 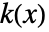 と帯域幅母数
と帯域幅母数 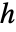 について
について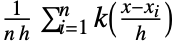 の線形補間バージョンで与えられる.
の線形補間バージョンで与えられる. - 帯域幅 bw の可能な指定値
-
h 使用する帯域幅 {"Standardized",h} 標準偏差の単位による帯域幅 {"Adaptive",h,s} 初期帯域幅 h,感度 s で適応的 Automatic 自動計算された帯域幅 "name" 名前付き帯域幅選択法を使う {bwx,bwy,…} x, y 等に別々の帯域幅指定 - 多変量密度については,h は正定対称行列でもよい.
- 適応的帯域幅については,感度 s は0から1までの実数あるいはAutomaticでなければならない.Automaticの場合,s は
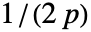 に設定される.ただし,
に設定される.ただし,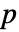 はデータの次元である.
はデータの次元である. - 使用可能な名前付き帯域幅選択メソッド
-
"LeastSquaresCrossValidation" 最小二乗クロス確認法を使う "Oversmooth" 標準Gaussianの1.08倍広い "Scott" Scottの規則を使った帯域幅選択 "SheatherJones" Sheather–Jonesプラグイン推定器を使う "Silverman" Silvermanの規則を使った帯域幅の決定 "StandardDeviation" 帯域幅として標準偏差を使う "StandardGaussian" 標準正規データの最適帯域幅 - デフォルトで"Silverman"メソッドが使われる.
- 自動帯域幅計算では,定配列は単位分散を持つとみなされる.
- 次のカーネル指定 ker が使える.
-
"Biweight" 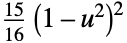
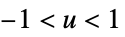
"Cosine" 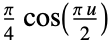
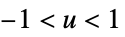
"Epanechnikov" 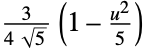
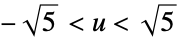
"Gaussian" 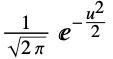
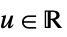
"Rectangular" 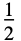
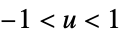
"SemiCircle" 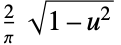
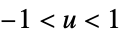
"Triangular" 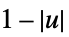
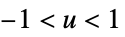
"Triweight" 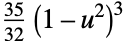
func 

- SmoothKernelDistributionが真の密度推定を生成するためには,関数 fn が有効な確率密度関数でなければならない.
- デフォルトで,"Gaussian"カーネルが使われる.
- カーネル関数 ker を指定し,{"Bounded",c,ker}を使ってもとになっている密度の既知の境界を構成することができる.ただし,c は任意の実数,c1<c2であるリスト{c1,c2},あるいは長さが data の次元と等しいリスト{{c11,c12},{c21,c22},…}でよい.
- 多変量密度については,{"Product",ker}と{"Radial",ker}を使ってカーネル関数 ker をそれぞれ積およびラジアルのタイプとして指定することができる.タイプの指定がない場合は積タイプのカーネルが使われる.
- 密度推定に用いられる精度は bw とデータで与えられる最低精度である.
- 使用可能なオプション
-
InterpolationPoints Automatic 使用する初期補間点の数 MaxMixtureKernels Automatic 使用するカーネルの最大数 MaxRecursion Automatic 許容する再帰下位区分の数 PerformanceGoal Automatic スピードまたは品質の最適化 MaxExtraBandwidths Automatic 使用するデータの範囲を超える最大帯域幅 - SmoothKernelDistributionはMean,CDF,RandomVariate等の関数で使うことができる.
例題
すべて開くすべて閉じる例 (2)
スコープ (37)
基本的な用法 (7)
分布特性 (8)
SmoothKernelDistributionと比較する:
帯域幅の選択 (12)
カーネル関数 (6)
これはNormalDistribution[0,1]の確率密度関数を使うのに等しい:
固定領域における推定 (4)
オプション (25)
InterpolationPoints (6)
MaxExtraBandwidths (6)
MaxMixtureKernels (6)
MaxRecursion (4)
PerformanceGoal (3)
デフォルトで,推定はスピードと品質の間でバランスを取って最適化されている:
スピードあるいは品質のPerformanceGoalを設定するか,Automaticを使って両者のバランスを取る:
PerformanceGoalを"Quality"に設定するとより時間がかかる:
ControlActiveと一緒に使ってPerformanceGoalを動的に変える:
アプリケーション (14)
TruncatedDistributionを使って平滑化の後の領域を限定する:
Casesと一緒に使って平滑化の前のデータ領域を限定する:
推定は左側ではデータを超えるがデータは正の値に限定されている:
MaxExtraBandwidthsを使ってデータを落とすことなく領域を限定する:
1990年代におけるS&P 500の日々の配当の差の分布を調べる:
オールド・フェイスフルの噴出時間と次の噴出までの待ち時間の結合分布を推定する:
SurvivalDistributionから返された推定を平滑化する:
生存時間が10より大きいとして25を超える生存確率を計算する:
ニューヨーク州バッファローにおける積雪量の確率密度関数の信頼帯を作る:
p 次元多変量正規データを仮定して,マハラノビス(Mahalanobis)距離が漸近的ChiSquareDistribution[p]であることを確認する:
四次元正規データを仮定した場合のマハラノビス距離が10を超える確率:
特性と関係 (8)
累積分布関数とSurvivalFunctionは区分的に二次である:
HazardFunctionは二次よりも一次で区分的に有理である:
SmoothKernelDistributionはもとになっている分布を一貫して推定する:
SmoothKernelDistributionはKernelMixtureDistributionの線形補間である:
SmoothKernelDistributionは,入力がTimeSeriesまたはEventSeriesのときのみ値に使うことができる:
SmoothKernelDistributionは,入力がTemporalDataのときは,すべての値に同時に働く:
考えられる問題 (4)
自動的に適応される帯域幅は,大きいサンプルには小さすぎるかもしれない:
初期帯域幅かMaxMixtureKernelsを大きくするか,感度を小さくするかする:
SmoothKernelDistributionはもとになっている分布の領域を知らない:
もとになっている分布は離散的であるが,推定された確率密度関数は連続的である:
重度に適応的な帯域幅の場合,これらの問題はそれほど明らかではない:
KernelMixtureDistributionは補間に依存しない記号的なメソッドを使う:
テキスト
Wolfram Research (2010), SmoothKernelDistribution, Wolfram言語関数, https://reference.wolfram.com/language/ref/SmoothKernelDistribution.html (2016年に更新).
CMS
Wolfram Language. 2010. "SmoothKernelDistribution." Wolfram Language & System Documentation Center. Wolfram Research. Last Modified 2016. https://reference.wolfram.com/language/ref/SmoothKernelDistribution.html.
APA
Wolfram Language. (2010). SmoothKernelDistribution. Wolfram Language & System Documentation Center. Retrieved from https://reference.wolfram.com/language/ref/SmoothKernelDistribution.html