FindDistributionParameters
FindDistributionParameters[data,dist]
求来自 data 的分布 dist 的参数估计.
FindDistributionParameters[data,dist,{{p,p0},{q,q0},…}]
求起始值为 p0、q0、… 的参数 p、q、….
更多信息和选项

- FindDistributionParameters 返回 dist 中参数的替换规则列表.
- data 必须是由来自给定分布 dist 的可能结果组成的列表.
- 分布 dist 可以是任意带未知参数的参数化一元、多元或导出分布.
- 可以给出下列选项:
-
AccuracyGoal Automatic 准确度目标 ParameterEstimator "MaximumLikelihood" 要使用何种参数估计量 PrecisionGoal Automatic 精确度目标 WorkingPrecision Automatic 内部计算所用的精确度 - 下列基本设置可用在 ParameterEstimator 上:
-
"MaximumLikelihood" 使对数似然函数最大化 "MethodOfMoments" 匹配原始矩 "MethodOfCentralMoments" 匹配中心矩 "MethodOfCumulants" 匹配累积量 "MethodOfFactorialMoments" 匹配阶乘矩 - 最大似然法试图最大化对数似然函数
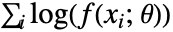 ,其中
,其中 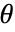 为分布参数,
为分布参数,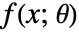 为分布的概率密度函数.
为分布的概率密度函数. - 矩法求解
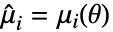 、
、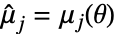 、
、 ,其中
,其中 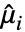 为
为 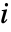
 阶样本矩,
阶样本矩,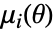 为参数为
为参数为 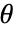 的分布的
的分布的 
 阶矩.
阶矩. - 基于矩法的估计量不一定满足对参数的所有限制条件.
范例
打开所有单元关闭所有单元范围 (15)
基本用法 (5)
选项 (4)
ParameterEstimator (3)
使用 FindMaximum 获得估计:
使用 EvaluationMonitor 提取被采样的点:
应用 (17)
获取另一个估计的起始值 (1)
不同语言中的单词长度 (1)
文本频率 (1)
将单词频率数据拟合为 ZipfDistribution:
以 rhohat 作为起始值,将最大为 50 的单词计数值拟合为一个截断的 ZipfDistribution:
地震震幅 (1)
求多峰 MixtureDistribution 模型的估计量:
将分布拟合为两种 NormalDistribution 分布的混合分布:
风速分析 (1)
将数据拟合为 RayleighDistribution:
股票值的市场变化 (1)
汽车的汽油效率 (1)
地震等待时间 (1)
该数据包含全世界于 1902 年 12 月 16 日至 1977 年 3 月 4 日之间的发生的主要地震(震幅大于等于 7.5,或死亡人数超过 1000)之间的相隔时间(以日记):
将相隔时间用 ExponentialDistribution 建模:
地震频率 (1)
水流流量 (1)
属性和关系 (8)
FindDistributionParameters 以替换规则形式给出估计:
EstimatedDistribution 给出插入了参数估计的分布:
FindProcessParameters 返回随机过程的参数估计列表:
FindDistributionParameters 返回分布的参数估计列表:
用 DistributionFitTest 测试拟合质量:
利用 SmoothKernelDistribution 得到非参数式核密度估计:
利用 SmoothHistogram 绘制非参数式密度的图形:
利用 Likelihood 计算似然值:
利用 LogLikelihood 计算对数似然值:
利用 Moment 计算数据的原始矩:
利用 QuantilePlot 绘制经验分位数相对理论分位数的图形:
当估计在 QuantilePlot 内部完成时,得到同一视图:
FindDistributionParameters 忽略 TimeSeries 和 EventSeries 中的时间戳:
对于 TemporalData,忽略所有路径结构:
文本
Wolfram Research (2010),FindDistributionParameters,Wolfram 语言函数,https://reference.wolfram.com/language/ref/FindDistributionParameters.html.
CMS
Wolfram 语言. 2010. "FindDistributionParameters." Wolfram 语言与系统参考资料中心. Wolfram Research. https://reference.wolfram.com/language/ref/FindDistributionParameters.html.
APA
Wolfram 语言. (2010). FindDistributionParameters. Wolfram 语言与系统参考资料中心. 追溯自 https://reference.wolfram.com/language/ref/FindDistributionParameters.html 年