LocationEquivalenceTest
LocationEquivalenceTest[{data1,data2,…}]
检验 datai 的均值或中位数是否相等.
LocationEquivalenceTest[{data1,…},"property"]
返回 "property" 的值.
更多信息和选项




- LocationEquivalenceTest 在 datai 上进行假设检验时,零假设
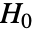 假定总体的真实位置参数相等,即
假定总体的真实位置参数相等,即 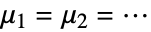 ,备择假设
,备择假设 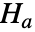 认为至少有一个是不同的.
认为至少有一个是不同的. - 缺省返回一个概率值或称
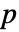 值.
值. - 小的
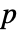 值表明
值表明 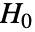 不可能为真.
不可能为真. - datai 必须为一元型 {x1,x2,…}.
- LocationEquivalenceTest[{data1,…}] 将根据数据选择效能最强的检验方法.
- LocationEquivalenceTest[{data1,…},All] 将选择适用于数据的所用检验.
- LocationEquivalenceTest[{data1,…},"test"] 报告基于 "test" 的
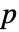 值.
值. - 基于均值的检验假定 datai 服从正态分布. 基于中位数的 Kruskal–Wallis 检验假定 datai 关于一个公共中位数对称. 完整区组
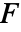 和 Friedman 秩检验都假定数据位于随机的完整区组中. 两种检验类型都要求 datai 有相等的方差.
和 Friedman 秩检验都假定数据位于随机的完整区组中. 两种检验类型都要求 datai 有相等的方差. - 可以使用下列检验:
-
"CompleteBlockF" 正态性,区组化 完全区组设计的均值检验 "FriedmanRank" 区组化 完全区组设计的中位数检验 "KruskalWallis" 对称性 两个或者更多个样本的中位数检验 "KSampleT" 正态性 两个或者更多个样本的均值检验 - 完全区组
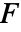 检验实际上对随机完全区组设计执行单向方差分析.
检验实际上对随机完全区组设计执行单向方差分析. - Friedman 秩检验在各行上对观测结果进行排序,并且对数据上各列的秩求和,以得到检验统计量. 在出现等值的情况下,对统计量进行校正.
- Kruskal–Wallis 检验对数据的秩执行单向方差分析.在出现等值的情况下,对统计量进行校正.
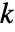 样本
样本 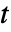 检验等价于数据的单向方差分析.
检验等价于数据的单向方差分析.- LocationEquivalenceTest[{data1,…},"HypothesisTestData"] 返回一个 HypothesisTestData 对象 htd,该对象可以通过利用格式 htd["property"] 提取额外的检验结果和属性.
- LocationEquivalenceTest[{data1,…},"property"] 可用于直接给出 "property" 的值.
- 与检验结果报告相关的性质包括:
-
"AllTests" 所有适用检验的列表 "AutomaticTest" 使用 Automatic 时所选择的检验 "DegreesOfFreedom" 检验中所用的自由度 "PValue" 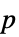 值列表
值列表"PValueTable" 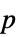 值的格式化表格
值的格式化表格"ShortTestConclusion" 检验结论的简单说明 "TestConclusion" 检验结论的说明 "TestData" 检验统计量与 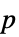 值的数对列表
值的数对列表"TestDataTable" 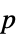 值与检验统计量的格式化表格
值与检验统计量的格式化表格"TestStatistic" 检验统计量的列表 "TestStatisticTable" 检验统计量的格式化表格 - 可以给出下列选项:
-
Method Automatic 用于计算 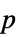 值的方法
值的方法SignificanceLevel 0.05 诊断与报告的截止值 VerifyTestAssumptions Automatic 应该验证的假定 - 对于位置检验,所选择的截止值
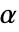 使得
使得 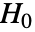 仅在
仅在 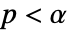 时被拒绝. 用于 "TestConclusion" 和 "ShortTestConclusion" 属性的
时被拒绝. 用于 "TestConclusion" 和 "ShortTestConclusion" 属性的 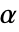 值由 SignificanceLevel 选项控制. 值
值由 SignificanceLevel 选项控制. 值 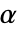 同时用于包括正态性、等方差与对称性检验在内的假定的诊断检验. 默认情况下,
同时用于包括正态性、等方差与对称性检验在内的假定的诊断检验. 默认情况下,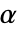 设为 0.05.
设为 0.05. - 在 LocationEquivalenceTest 中,VerifyTestAssumptions 的命名设置包括:
-
"Normality" 验证所有数据为正态分布 "EqualVariance" 验证 datai 的方差相等 "Symmetry" 验证关于一个共同的中位数的对称性
范例
打开所有单元关闭所有单元基本范例 (3)
对于重复提取的性质,创建一个 HypothesisTestData 对象:
范围 (9)
检验 (5)
对于重复提取的性质,创建一个 HypothesisTestData 对象:
从一个 HypothesisTestData 对象中提取某些性质:
选项 (8)
Method (2)
经过尺度缩放后的检验统计量服从 FRatioDistribution:
SignificanceLevel (3)
应用 (4)
这里有两种不同的螃蟹,分别对雌雄两种螃蟹测量一些形态学特征. 判断在不同组中这些测量结果是否不同:
对 75 个患有II型糖尿病的病人进行一项前导性研究,这些病人在某种特定药物治疗下没有达到预期的减肥目标. 把这些病人随机分成3组:一个对照组继续之前的药物治疗,两个治疗组接受剂量分别为50和100毫克的新药物的治疗. 记录 12 周内的体重减少量(以磅为单位):
在成对差值检验中,使用 Bonferroni 校正,结果显示这两个治疗组的水平高于对照组,但是它们彼此之间没有显著不同:
6 位食品评论家对四个餐馆的质量进行评估,他们采用的是 100 分制的评估方法. 根据这些评估结果,判断这四家餐馆的质量是否有显著差异:
属性和关系 (12)
由 ![]() 样本
样本 ![]() 检验返回的
检验返回的 ![]() 值等价于两个样本的 TTest 得到的值:
值等价于两个样本的 TTest 得到的值:
Kruskal–Wallis检验是双样本Mann–Whitney检验的一个![]() 样本扩展:
样本扩展:
在 ![]() 下,
下,![]() 样本
样本 ![]() 检验的统计量服从一个 FRatioDistribution[g-1,n-g],其中 g 是数据集的数目,而 n 是测量结果的总数:
检验的统计量服从一个 FRatioDistribution[g-1,n-g],其中 g 是数据集的数目,而 n 是测量结果的总数:
在 ![]() 下,完全区组
下,完全区组 ![]() 和 Friedman 秩检验统计量(带有 t 个处理方法和 g 个区组)服从一个 FRatioDistribution[t-1,(g-1)(t-1)]:
和 Friedman 秩检验统计量(带有 t 个处理方法和 g 个区组)服从一个 FRatioDistribution[t-1,(g-1)(t-1)]:
可以对 Friedman 统计量进行变换,使之服从 ChiSquareDistribution[g-1]:
利用 ChiSquareDistribution 计算 ![]() 值:
值:
通过把 Method 设为 "Asymptotic",自动完成变换:
在 ![]() 下,Kruskal–Wallis检验统计量渐进服从ChiSquareDistribution[g-1],其中 g 是数据集的数目:
下,Kruskal–Wallis检验统计量渐进服从ChiSquareDistribution[g-1],其中 g 是数据集的数目:
默认情况下,对检验统计量重新调整尺寸以服从 FRatioDistribution[g-1,n-g]:
LocationEquivalenceTest 检验这个比值与1的差异有多大:
![]() 和
和 ![]() 检验统计量也用于 LocationEquivalenceTest 中:
检验统计量也用于 LocationEquivalenceTest 中:
对于 ![]() 样本
样本 ![]() 和 Kruskal–Wallis检验,检验统计量可以使用 LinearModelFit 计算得到:
和 Kruskal–Wallis检验,检验统计量可以使用 LinearModelFit 计算得到:
Kruskal–Wallis检验是类似的,但它使用了排序方法:
对两组数据使用 LocationTest:
LocationTest 也可以检验更复杂的假设:
输入是 TimeSeries 时位置等价测试会忽略时间戳:
位置等效检验可以识别 TemporalData 的路径结构:
可能存在的问题 (3)
文本
Wolfram Research (2010),LocationEquivalenceTest,Wolfram 语言函数,https://reference.wolfram.com/language/ref/LocationEquivalenceTest.html.
CMS
Wolfram 语言. 2010. "LocationEquivalenceTest." Wolfram 语言与系统参考资料中心. Wolfram Research. https://reference.wolfram.com/language/ref/LocationEquivalenceTest.html.
APA
Wolfram 语言. (2010). LocationEquivalenceTest. Wolfram 语言与系统参考资料中心. 追溯自 https://reference.wolfram.com/language/ref/LocationEquivalenceTest.html 年