Dataset
Dataset[data]
表示基于列表和关联层次结构的结构化数据集.
更多信息和选项



- Dataset 不仅可以表示数据的完整矩形多维数组,也可以表示任意的树结构,对应于具有任意层次结构的数据.
- 根据它所包含的数据,Dataset 对象通常显示为元素的表格或网格.
- 像 Map、Select 之类的函数可以通过写入 Map[f,dataset], Select[dataset,crit] 等直接应用于 Dataset.
- Dataset 对象中数据的子集可以通过写入 dataset[[parts]] 获得.
- Dataset 对象也可以使用专门的查询语法通过写入 dataset[query] 进行查询.
- 尽管列表和关联的任意嵌套是可能的,二维(表格)形式是最常用的.
- 下表显示了一个 Dataset 的常见显示形式、它所包含的 Wolfram 语言表达式形式、和它的结构的逻辑诠释之间的对应关系:
-

{{◻,◻,◻},
{◻,◻,◻},
{◻,◻,◻},
{◻,◻,◻}}
列表的列表行和列都没有命名的表格 
{<"x"◻,"y"◻,…>,
<"x"◻,"y"◻,…>,
<"x"◻,"y"◻,…> }
关联的列表具有命名列的表格 
<"a"{◻,◻},
"b"{◻,◻},
"c"{◻,◻},
"d"{◻,◻}>
列表的关联具有命名行的表格 
<"a"<"x"◻,"y"◻>,
"b"<"x"◻,"y"◻>,
"c"<"x"◻,"y"◻>>
关联的关联具有命名列和命名行的表格 - Dataset 按行诠释嵌套列表和关联,使得数据的第 1 层(最外层)被诠释为表格的行,第 2 层被诠释为表格的列.
- 已命名的行和列分别对应第 1 层和第 2 层的关联,其键值是含有名称的字符串. 未命名的行和列对应于这些层上的列表.
- 数据集的行和列可以通过写入 Transpose[dataset] 互换.
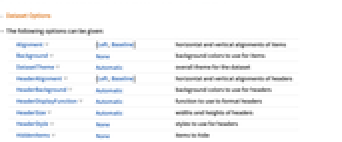
- 可给出以下选项:
-
Alignment {Left,Baseline} 条目的水平和垂直对齐 Background None 条目的背景色 DatasetTheme Automatic 数据集的整体外观主题 HeaderAlignment {Left,Baseline} 标题的水平和垂直对齐 HeaderBackground Automatic 标题的背景色 HeaderDisplayFunction Automatic 用来格式化标题的函数 HeaderSize Automatic 标题的宽度和高度 HeaderStyle None 标题的样式 HiddenItems None 要隐藏起来的条目 ItemDisplayFunction Automatic 用来格式化条目的函数 ItemSize Automatic 条目的宽度和高度 ItemStyle None 行和列的样式 MaxItems Automatic 最多显示多少个条目 - 除了 HiddenItems、MaxItems 和 DatasetTheme,可按以下方式给出选项的设置,分别应用于不同的条目:
-
spec 对所有条目应用 spec {speck} 对相邻层级应用 speck {spec1,spec2,…, specn,rules} 为特定部分指定明确的规则 - speck 可具有以下形式:
-
{s1,s2,…,sn} 使用 s1 到 sn,然后使用默认值 {{c}} 所有情况下都使用 c {{c1,c2}} 交替使用 c1 和 c2 {{c1,c2,…}} 循环使用所有 ci {s,{c}} 先使用 s,然后重复使用 c {s1,{c},sn} 先使用 s1,然后重复使用 c,最后使用 sn {s1,s2,…,{c1,c2,…},sm,…,sn} 开始时使用第一个 si 序列,然后循环使用 ci,最后使用后面的 si {s1,s2,…,{},sm,…,sn} 开始时使用第一个 si 序列, 最后使用后面的序列 - 采用形式为 {s1,s2,…,{…},sm,…,sn} 的设置时,如果指定的 si 比数据集中的条目多,将开始的 si 用于前面的条目,将后面的设置用于最后的那些条目.
- 规则的形式为 ispec,其中 i 指定 Dataset 中的一个位置. 位置也可以是模式.
- 鼠标悬停在元素上时,可以在数据集的底部读取元素的位置.
- 可用以下形式给出 MaxItems 的设置:
-
m 显示 m 个行 {m1, m2,…,mn} 显示数据集层级 i 的 mi 条目 - 对于 MaxItems,Automatic 表示应显示默认数量的条目.
- 可用以下形式给出 HiddenItems 的设置:
-
i 隐藏位置 i 处的条目 {i1,i2,…,in} 隐藏位置 ik 处的条目 {…, iFalse,…} 显示位置 i 处的条目 {…, iTrue,…} 隐藏位置 i 处的条目 - 在 HiddenItems 列表中,新的设置会覆盖以前的设置.
- ItemDisplayFunction 和 HeaderDisplayFunction 的个别设置为纯函数,返回要显示的条目. 这些函数接受三个参数:条目的值、条目的位置和包含该条目的数据集.
- 在 ItemStyle 和 HeaderStyle 的设置的某些位置,明确的规则可被解释为 ispec. 如果要使用样式选项,则将规则与 Directive 封装在一起.
- 在诸如 Alignment、HeaderAlignment、ItemSize 和 HeaderSize 这样的选项中,也许有列表出现,可能的情况下,将顶层列表解释为单个选项值,否则将其解释为适用于连续 Dataset 层级的值列表.
- 如果规则的左侧不是列表,则该设置适用于将左侧作为键或索引的任何位置.
- 可用返回设置的纯函数 f 代替任何设置. 设置由 f[item,position,dataset] 给出.
- Normal 可用于将任何 Dataset 对象转换为其底层数据,该数据通常是列表和关联关系的组合.
- 语法 dataset[[parts]] 或 Part[dataset,parts] 可用于提取 Dataset 的部分.
- 可以从 Dataset 提取的部分包括 Part 的所有普通规范.
- 与 Part 的普通行为不同,如果 Dataset 的指定子部分不存在,则在结果的相应位置生成 Missing["PartAbsent",…].
- 以下部分运算通常用于从表格数据集提取行:
-
dataset[["name"]] 提取已命名的行(如适用) dataset[[{"name1",…}]] 提取一组已命名的行 dataset[[1]] 提取第一行 dataset[[n]] 提取第 n 行 dataset[[-1]] 提取最后一行 dataset[[m;;n]] 提取行 m 至 n dataset[[{n1,n2,…}]] 提取一组已编号的行 - 以下部分运算通常用于从表格数据集提取列:
-
dataset[[All,"name"]] 提取已命名的列(如适用) dataset[[All,{"name1",…}]] 提取一组已命名的列 dataset[[All,1]] 提取第一列 dataset[[All,n]] 提取第 n 列 dataset[[All,-1]] 提取最后一列 dataset[[All,m;;n]] 提取列 m 至 n dataset[[All,{n1,n2,…}]] 提取列的子集 - 像 Part 一样,行和列运算可以组合使用. 一些范例包括:
-
dataset[[n,m]] 取位于第 n 行和第 m 列的单元 dataset[[n,"colname"]] 提取第 n 行已命名列的值 dataset[["rowname","colname"]] 提取位于已命名行和列的单元 - 下面的运算可以用来除去来自行和列的标签,实际上相当于将关联变成列表:
-
dataset[[Values]] 去除行标记 dataset[[All,Values]] 去除列标记 dataset[[Values,Values]] 去除行和列标记 - 查询语法 dataset[op1,op2,…] 可以被认为是 Part 语法的扩展,以允许应用聚合和变换,以及取数据的子集.
- 查询的一些常见形式包括:
-
dataset[f] 将 f 应用于整个表格 dataset[All,f] 将 f 应用于表格的每一行 dataset[All,All,f] 将 f 应用于表格的每一单元 dataset[f,n] 提取第 n  列,然后对其应用 f
列,然后对其应用 fdataset[f,"name"] 提取已命名的列,然后对其应用 f dataset[n,f] 提取第 n  行,然后对其应用 f
行,然后对其应用 fdataset["name",f] 提取已命名的行,然后对其应用 f dataset[{nf}] 选择性地将 f 映射到第 n  行
行dataset[All,{nf}] 选择性地将 f 映射到第 n  列
列 - 一些更专业的查询形式包括:
-
dataset[Counts,"name"] 给出已命名列中不同值的个数 dataset[Count[value],"name"] 给出已命名列中 value 的出现次数 dataset[CountDistinct,"name"] 计算已命名列中不同值的个数 dataset[MinMax,"name"] 给出已命名列中的最小值和最大值 dataset[Mean,"name"] 给出已命名列的平均值 dataset[Total,"name"] 给出已命名列的总值 dataset[Select[h]] 提取满足条件 h 的行 dataset[Select[h]/*Length] 计算满足条件 h 的行的个数 dataset[Select[h],"name"] 选择行,然后从结果中提取已命名的列 dataset[Select[h]/*f,"name"] 选择行,提取已命名列,然后对其应用 f dataset[TakeLargestBy["name",n]] 给出 n 行,使其已命名的列最大 dataset[TakeLargest[n],"name"] 给出已命名列中的 n 个最大值 - 在 dataset[op1,op2,…] 中,查询运算符 opi 按顺序层层深入逐步应用于数据,对于任何给定的运算符,可以按“降序”应用到数据中,也可以按“升序”应用到数据中.
- 组成 Dataset 查询的运算符分为以下几大类,具有不同的升序和降序行为:
-
All,i,i;;j,"key",… 降序 部分运算符 Select[f],SortBy[f],… 降序 筛选运算符 Counts,Total,Mean,… 升序 聚集运算符 Query[…],… 升序 子查询运算符 Function[…],f 升序 任意函数 - “降序”运算符在随后的运算符被应用到更深层之前,应用于原始数据集的相应部分.
- 降序运算符的一个特征是,它们在一定层上应用时,不改变数据的更深层次的结构. 这保证了随后的运算符将遇到的子表达式,其结构与原始数据集的相应层次是相同的.
- 最简单的降序运算符是 All,它选取给定层的所有部分,从而使得数据结构在该层保持不变. All 可以安全地被替换为任何其他降序运算符,以得到其它有效查询.
- “升序”运算符在所有随后的运算符应用于更深层次之后被应用. 降序运算符对应于原始数据的层,而升序运算符对应于结果的层.
- 与降序运算符不同,升序运算符不必保持所运算数据的结构. 运算符一般被认为是升序的,除了被特别认定为降序的情况外.
- “降序”部分运算符指定在任何随后的运算符被应用于更深层次前,在某一层上应该选取哪些元素:
-
All 将随后的运算符应用于列表或关联的每个部分 i;;j 取 i 至 j 的部分,并将随后的运算符应用于每个部分 i 仅取部分 i,并将随后的运算符应用于该部分 "key",Key[key] 取关联的 key 值,并对其应用随后的运算符 Values 取关联的值,并对每个值应用随后的运算符 {part1,part2,…} 取给定的部分,并对每个部分应用随后的运算符 - “降序”筛选运算符指定将随后的运算符应用于更深层次前,在某一层上如何重新安排或筛选元素:
-
Select[test] 只选取满足 test 的列表或关联的部分 SelectFirst[test] 选取满足 test 的第一个部分 KeySelect[test] 选取键值满足 test 的关联的部分 TakeLargestBy[f,n],TakeSmallestBy[f,n] 选取 n 个元素,其中 f[elem] 以排序顺序为最大或最小 MaximalBy[crit],MinimalBy[crit] 选取使得准则 crit 大于或小于所有其他元素的部分 SortBy[crit] 按 crit 的顺序对各部分排序 KeySortBy[crit] 根据键值对关联的部分进行排序,按 crit 的顺序 DeleteDuplicatesBy[crit] 选取按照 crit 来看唯一存在的部分 DeleteMissing 丢弃标头为 Missing 的元素 - 语法 op1/*op2 可用于将两个或多个筛选运算符合并成一个运算符,但仍在一个单一的层运算.
- “升序”聚集运算符将应用随后运算符于更深层次所得的结果进行合并或汇总:
-
Total 结果中总量值的和 Min,Max 给出结果中的最小和最大量值 Mean,Median,Quantile,… 给出结果的统计汇总 Histogram,ListPlot,… 计算结果中的可视化 Merge[f] 使用函数 f 合并结果中关联的公共键 Catenate 将列表或关联的元素连接 Counts 给出关联,计算结果中值所出现的次数 CountsBy[crit] 给出关联,根据 crit 计算值所出现的次数 CountDistinct 给出结果中不同值的个数 CountDistinctBy[crit] 给出关联,根据 crit 给出结果中不同值的个数 TakeLargest[n],TakeSmallest[n] 取最大或最小的 n 个元素 - 语法 op1/*op2 可用于将两个或多个聚集运算符合并成一个运算符,但仍在一个单一的层运算.
- “升序”子查询运算符在将随后的运算符应用于更深层次后执行子查询:
-
Query[…] 对结果执行子查询 {op1,op2,…} 对结果同时应用多个运算符,生成一个列表 <key1op1,key2op2,…> 对结果同时应用多个运算符,生成具有给定键的关联 {key1op1,key2op2,…} 对结果的指定部分应用不同的运算符 - 当一个或多个降序运算符由一个或多个升序运算符(如 desc/*asc)组成时,降序部分将被应用,然后随后的运算符将应用于更深层次,最后升序部分将在那一层应用于结果.
- 特殊“降序”运算符 GroupBy[spec] 将在它所出现的那一层引入新的关联,并可以从现有的查询中插入或去除,而不影响随后的运算符.
- 诸如 CountsBy、GroupBy 和 TakeLargestBy 之类的函数通常取另一个函数作为它们的参数. 当与 Dataset 中的关联一起使用时,往往使用这种"by"函数来查找表格中某一列的值.
- 为此,Dataset 查询允许语法 "string" 在这种语境下表示 Key["string"]. 例如,查询运算符 GroupBy["string"] 在被执行之前自动重写为 GroupBy[Key["string"]].
- 相似地,表达式 GroupBy[dataset,"string"] 被重写为 GroupBy[dataset,Key["string"]].
- 如果可能的话,类型推断用于确定查询是否成功. 被推断为失败的将导致返回 Failure 对象,而不执行该查询.
- 在默认情况下,如果在查询过程中有任何信息产生,查询将被中止,并且返回包含该信息的 Failure 对象.
- 当查询返回结构化数据(例如列表或关联,或这些的嵌套组合)时,其结果将以另一个 Dataset 对象的形式给出. 否则,结果将作为一个普通的 Wolfram 语言表达式给出.
- 如要了解关于 Dataset 查询特殊行为的更多信息,请参阅 Query 的函数页面.
- Import 和 SemanticImport 可用于将文件作为 Dataset 对象从如 "CSV" 和 "XLSX" 等格式导入.
- Dataset 对象可以通过 Export 导出为如 "CSV"、"XLSX" 和 "JSON" 这样的格式.
数据集结构
数据集的选项
部分运算
数据集查询
降序和升序查询运算符
部分运算符
筛选运算符
聚集运算符
子查询运算符
特殊运算符
快捷语法
查询行为
导入和导出
范例
打开所有单元关闭所有单元选项 (42)
Background (10)
HeaderStyle (4)
ItemStyle (6)
应用 (3)
表格(关联列表) (1)
编号表格(关联的关联) (1)
分层数据(其他数据的关联的关联) (1)
底层数据是一个关联,其键是国家,而它们的值是行政区划及人口的进一步关联:
传递给 ListLogPlot 的底层数据是列表的关联,每个长度均为 2:
属性和关系 (4)
Query 是 Dataset 所支持的查询语言的运算符形式:
使用 EntityValue 从 Wolfram 知识库获得 Entity 对象的属性的 Dataset:
使用 SemanticImport 将文件导入为 Dataset:
以 "JSON" 格式导出样本:
以 "CSV" 格式导出样本:
可能存在的问题 (3)
如果查询的子运算被推断为失败,整个查询将不被执行,并将返回一个 Failure 对象:
默认情况下,如果有任何信息在 Dataset 的运算过程中生成,则将返回一个 Failure 对象:
如要指定不同的行为,使用显式的 Query 表达式,并与选项 FailureAction 结合:
文本
Wolfram Research (2014),Dataset,Wolfram 语言函数,https://reference.wolfram.com/language/ref/Dataset.html (更新于 2021 年).
CMS
Wolfram 语言. 2014. "Dataset." Wolfram 语言与系统参考资料中心. Wolfram Research. 最新版本 2021. https://reference.wolfram.com/language/ref/Dataset.html.
APA
Wolfram 语言. (2014). Dataset. Wolfram 语言与系统参考资料中心. 追溯自 https://reference.wolfram.com/language/ref/Dataset.html 年