DistributionFitTest
DistributionFitTest[data]
data が正規分布に従っているかどうかの検定を行う.
DistributionFitTest[data,dist]
data が dist に従った分布かどうかの検定を行う.
DistributionFitTest[data,dist,"property"]
"property"の値を返す.
詳細とオプション




- DistributionFitTestは data が分布 dist の母集団から得られたという帰無仮説
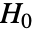 およびそうではないという対立仮説
およびそうではないという対立仮説 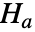 で適合度仮説検定を実行する.
で適合度仮説検定を実行する. - デフォルトで,確率値つまり
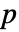 値が返される.
値が返される. - 小さい
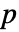 値は data が dist から来ている可能性が低いことを示す.
値は data が dist から来ている可能性が低いことを示す. - dist は,記号または数値の母数,またはデータ集合,を持つ任意の記号分布でよい.
- data は一変量{x1,x2,…}でも多変量{{x1,y1,…},{x2,y2,…},…}でもよい.
- DistributionFitTest[data,dist,Automatic]は一般的な対立仮説に対して data と dist に当て嵌まる最も強力な検定を選ぶ.
- DistributionFitTest[data,dist,All]は data と dist に適用されるすべての検定を選ぶ.
- DistributionFitTest[data,dist,"test"]は"test"に従って
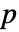 値をレポートする.
値をレポートする. - 多くの検定が,検定分布 dist の累積分布関数
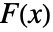 ,データの経験的累積分布関数
,データの経験的累積分布関数 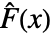 ,それらの差分
,それらの差分 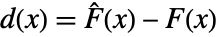 と
と 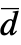 =Expectation[d(x),…]を使う.累積分布関数である
=Expectation[d(x),…]を使う.累積分布関数である 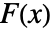 と
と 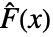 は帰無仮説
は帰無仮説 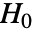 下で同じでなければならない.
下で同じでなければならない. - 次の検定は一変量分布と多変量分布に使える.
-
"AndersonDarling" 分布,データ Expectation[ 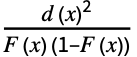 ]に基づく
]に基づく"CramerVonMises" 分布,データ Expectation[d(x)2]に基づく "JarqueBeraALM" 正規性 歪度と尖度に基づく "KolmogorovSmirnov" 分布,データ ![sup_x TemplateBox[{{d, (, x, )}}, Abs]](Files/DistributionFitTest.ja/14.png "sup_x TemplateBox[{{d, (, x, )}}, Abs]") に基づく
に基づく"Kuiper" 分布,データ 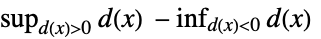 に基づく
に基づく"PearsonChiSquare" 連続,データ 期待ヒストグラムと観察ヒストグラムに基づく "ShapiroWilk" 正規性 変位値に基づく "WatsonUSquare" 分布,データ Expectation[ 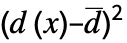 ]に基づく
]に基づく - 次の検定は多変量分布に使用できる.
-
"BaringhausHenze" 正規性 経験的特性関数に基づく "DistanceToBoundary" 一様性 一様境界までの距離に基づく "MardiaCombined" 正規性 Mardia歪度とMardia尖度の組合せ "MardiaKurtosis" 正規性 多変量の尖度に基づく "MardiaSkewness" 正規性 多変量の歪度に基づく "SzekelyEnergy" データ Newtonのポテンシャルエネルギーに基づく - DistributionFitTest[data,dist,"property"]を使って"property"の値を直接与えることができる.
- 検定結果のレポートに関連する特性
-
"AllTests" 適用可能なすべての検定のリスト "AutomaticTest" Automaticが使われた場合に選ばれる検定 "DegreesOfFreedom" 検定で使われる自由度 "PValue" 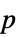 値のリスト
値のリスト"PValueTable" 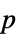 値のフォーマットされた表
値のフォーマットされた表"ShortTestConclusion" 検定結果の簡単な説明 "TestConclusion" 検定結果の説明 "TestData" 検定統計量と 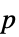 値のペアのリスト
値のペアのリスト"TestDataTable" 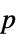 値と検定統計量のフォーマットされた表
値と検定統計量のフォーマットされた表"TestStatistic" 検定統計量のリスト "TestStatisticTable" 検定統計量のフォーマットされた表 "HypothesisTestData" HypothesisTestDataオブジェクトを返す - DistributionFitTest[data,dist,"HypothesisTestData"]はHypothesisTestDataオブジェクト htd を返す.このオブジェクトを使って,追加的な検定結果と htd["property"]の形式で特性を取り出すことができる.
- データ分布に関連する特性
-
"FittedDistribution" データのフィットした分布 "FittedDistributionParameters" データの分布母数 - 使用可能なオプション
-
Method Automatic 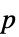 値をの計算に使用するメソッド
値をの計算に使用するメソッドSignificanceLevel 0.05 診断とレポートのための切捨て - 適合度検定では,
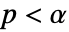 のときにのみ
のときにのみ 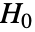 が棄却されるような切捨て
が棄却されるような切捨て 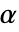 が選択される.特性"TestConclusion"および"ShortTestConclusion"で使われる
が選択される.特性"TestConclusion"および"ShortTestConclusion"で使われる 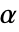 の値はSignificanceLevelオプションで制御される.デフォルトの
の値はSignificanceLevelオプションで制御される.デフォルトの 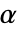 は0.05である.
は0.05である. - Method->"MonteCarlo"の設定では,入力 siと同じ長さの
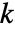 個のデータ集合が
個のデータ集合が 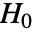 のもとにフィットされた分布を使って生成される.次に,DistributionFitTest[si,dist,{"TestStatistic",test}]からのEmpiricalDistributionを使って
のもとにフィットされた分布を使って生成される.次に,DistributionFitTest[si,dist,{"TestStatistic",test}]からのEmpiricalDistributionを使って 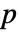 値が推定される.
値が推定される.
例題
すべて開くすべて閉じる例 (3)
さらに特性を抽出するためにHypothesisTestDataオブジェクトを作成する:
検定結果をProbabilityPlotで証明する:
スコープ (22)
検定 (16)
第3引数をAutomaticに指定して,一般に検出力が高く適切な検定を適用する:
特性"AutomaticTest"はどの検定を選択したかを知るのに使われる:
WeibullDistribution[1,2]に対するよいフィットを棄却するための十分な証拠はない:
![]() 値は混合から得られたのではないデータに比べて混合データの場合には大きい:
値は混合から得られたのではないデータに比べて混合データの場合には大きい:
正規分布に従うデータの ![]() 値は,一般に,正規分布には従わないデータのそれよりも大きい:
値は,一般に,正規分布には従わないデータのそれよりも大きい:
MultinormalDistributionと多変量のUniformDistributionの検定をそれぞれ行う:
同じ分布に従うデータ間の ![]() 値は異なる分布に従うデータ間のそれよりも大きい:
値は異なる分布に従うデータ間のそれよりも大きい:
特性"AllTests"を使ってどの検定が使われたかを調べる:
繰り返し特性を抽出するためにHypothesisTestDataオブジェクトを作成する:
HypothesisTestDataオブジェクトからいくつかの特性を抽出する:
データ特性 (2)
オプション (6)
Method (4)
アプリケーション (12)
QuantilePlotの経験的累積分布関数と理論的累積分布関数を視覚的に比較する:
Jarque–Bera ALM検定とShapiro–Wilk検定を使って正規性を算定する:
SmoothHistogramは検定結果と一致する:
QuantilePlotは比較的よいフィットを示している:
適合度検定を使ってヒストグラムのような可視化が示すフィットを確かめる:
Kolmogorov–Smirnov検定はヒストグラムが示す適合フィットと一致する:
最も明るい100個の星の絶対的な大きさが正規分布に従うかどうか調べる:
境界までの距離(Distance-to-Boundary)検定を使う:
Szekelyのエネルギー検定を使って2つの多変量データ集合を比較する:
Kuiperの検定とWatsonの ![]() 検定は円の上での均一性の検定に役立つ:
検定は円の上での均一性の検定に役立つ:
最初のデータ集合はランダムに分布しており,2番目のデータ集合はクラスタ化している:
モデルがS&P 500指標の日々の点の変化に適しているかどうか調べる:
非常に大きいデータ集合では,検定分布からの小さい偏差も容易に検出される:
LinearModelFitからの残差を正規性について調べる:
Shapiro–Wilk検定は残差が正規分布に従っていないことを示している:
QuantilePlotでは分布の左裾部に大きい偏差が現れる:
検定統計量の分布のシミュレーションを行いモンテカルロの ![]() 値を得る:
値を得る:
SmoothHistogramを使って検定統計量の分布を可視化する:
Anderson–Darling検定からモンテカルロの ![]() 値を得る:
値を得る:
DistributionFitTestによって返された ![]() 値と比較する:
値と比較する:
もとになる分布がStudentTDistribution[2],検定規模が0.05,サンプルサイズが35の場合のShapiro–Wilk検定の検出力を推定する:
カーネル密度推定を使ったデータ集合の平滑化で,データのもとになっている分布の構造を保存しつつ,ノイズを除去することができる.以下で同じ分布からの2つのデータ集合を作る:
特性と関係 (16)
デフォルトで,一変量データはNormalDistributionと比較される:
デフォルトで,多変量データはMultinormalDistributionと比較される:
分布母数が指定されていない場合,それはデータから推定される:
検定分布で母数が指定されていない場合には最尤度推定が使われる:
検定サイズを0.05にすると,結果として約5%の ![]() が誤って棄却される:
が誤って棄却される:
タイプIIのエラーは,誤りであるにもかかわらず ![]() が棄却されない場合に起る:
が棄却されない場合に起る:
有効な検定の ![]() 値は
値は ![]() のもとでUniformDistribution[{0,1}]である:
のもとでUniformDistribution[{0,1}]である:
Kolmogorov–Smirnov検定を使って一様性を調べる:
各検定の検出力は ![]() が誤りであるときにこれを棄却する確率である:
が誤りであるときにこれを棄却する確率である:
これらの条件下では,ピアソン(Pearson)の ![]() 検定の検出力が最も低い:
検定の検出力が最も低い:
各検定の検出力はサンプルサイズが小さくなるに従って減少する:
検定の中にはサンプルサイズが小さくても他の検定よりよい結果を出すものもある:
場所による差の検出に向いている検定とそうではない検定がある:
ピアソンの ![]() 検定の検出力を高めるためには大きいサンプルサイズが必要である:
検定の検出力を高めるためには大きいサンプルサイズが必要である:
Jarque–Bera ALM検定とShapiro–Wilk検定はサンプルが小さい場合の検出力が最も大きい:
調べる分布の特性によって異なる検定を使う.ある特定の検定に基づいた結果が,常に他の検定に基づいた結果と一致するとは限らない:
緑色の領域は両方の検定による正しい結果である.両方の検定でタイプIIのエラーが認められた場合には,赤色の領域に点が置かれている.灰色の領域は検定結果が一致しない部分である:
分布のフィット検定は,入力がTimeSeriesのときにのみ値に使うことができる:
テキスト
Wolfram Research (2010), DistributionFitTest, Wolfram言語関数, https://reference.wolfram.com/language/ref/DistributionFitTest.html (2015年に更新).
CMS
Wolfram Language. 2010. "DistributionFitTest." Wolfram Language & System Documentation Center. Wolfram Research. Last Modified 2015. https://reference.wolfram.com/language/ref/DistributionFitTest.html.
APA
Wolfram Language. (2010). DistributionFitTest. Wolfram Language & System Documentation Center. Retrieved from https://reference.wolfram.com/language/ref/DistributionFitTest.html