NearestNeighborG
NearestNeighborG[pdata,r]
估计点数据 pdata 半径为 r 时的最近邻函数 ![]() .
.
NearestNeighborG[pproc,r]
计算点过程 pproc 的 ![]() .
.
NearestNeighborG[bdata,r]
计算已分组数据 bdata 的 ![]() .
.
NearestNeighborG[pspec]
生成可重复应用于不同半径 r 的函数 ![]() .
.
更多信息和选项




- NearestNeighborG 亦称为最近邻函数和最近邻分布.
- 函数
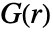 给出了在 pdata 或 pproc 中在距一个点
给出了在 pdata 或 pproc 中在距一个点  的范围内找到另一个点的概率.
的范围内找到另一个点的概率. -
- 与泊松点过程进行比较时,结果为:
-
- 半径 r 可以是单个值或数值列表. 如果没有指定半径 r,NearestNeighborG 返回可用来重复计算
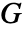 函数的 PointStatisticFunction.
函数的 PointStatisticFunction. - 可用以下形式给出点 pdata:
-
{p1,p2,…} 点 pi GeoPosition[…],GeoPositionXYZ[…],… 地理点 SpatialPointData[…] 空间点集 {pts,reg} 点集 pts 和观察区域 reg - 如果没有给出观察区域 reg,则用 RipleyRassonRegion 自动计算区域.
- 可用以下形式给出点过程 pproc:
-
proc 点过程 proc {proc,reg} 点过程 proc 和观察区域 reg - 观察区域 reg 不应含有参数且 SpatialObservationRegionQ 的结果为真.
- 已分组数据 bdata 来自 SpatialBinnedPointData,且被视为是具有分段恒定强度函数的 InhomogeneousPoissonPointProcess.
- 对于 pdata,通过离散化观察区域并假定恒定点强度来计算
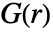 .
. - 对于 pproc,通过使用精确公式或通过仿真生成点数据来计算
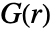 .
. - 可给出以下选项:
-
Method Automatic 使用什么方法 SpatialBoundaryCorrection Automatic 使用什么样的边界校正 - 对于 SpatialBoundaryCorrection,可使用以下设置:
-
Automatic 自动确定边界校正 None 不进行边界校正 "BorderMargin" 对于观察区域使用内边界 "Hanisch" 丢弃到最近邻居的距离大于到边界的距离的点 "KaplanMeier" SurvivalDistribution 方法:用到区域边界的距离来删失到最近邻居的距离 "NelsonAalen" SurvivalDistribution 方法:用到区域边界的距离来删失到最近邻居的距离 - 设置 Method->{"Discretization"->opts} 允许对估计中的离散化方法进行调整. 此处 opts 可以是 DiscretizeRegion 的任意有效选项.
范例
打开所有单元关闭所有单元基本范例 (3)
范围 (8)
点数据 (5)
将 NearestNeighborG 与 SpatialPointData 一起使用:
创建一个 PointStatisticFunction 以备后用:
将 NearestNeighborG 和 GeoPosition 一起使用:
点过程 (3)
PoissonPointProcess 的最近邻函数有解析形式:
指定维度的聚类过程 ThomasPointProcess 的最近邻函数:
指定维度的聚类过程 MaternPointProcess 的最近邻函数:
选项 (2)
SpatialBoundaryCorrection (2)
不包含边界校正的 NearestNeighborG 估计器存在偏差,除非是处理较大的点集,否则不应使用:
默认方法 "BorderMargin" 仅考虑距边界 ![]() 的点:
的点:
"Hanisch" 方法对观察区域中的每个点进行加权,以使估计值无偏差:
"KaplanMeier" 和 "NelsonAalen" 方法是 SurvivalDistribution 中使用的估计器. 用每个点到观察区域的边界的距离来删失到最近邻居的距离:
应用 (5)
属性和关系 (2)
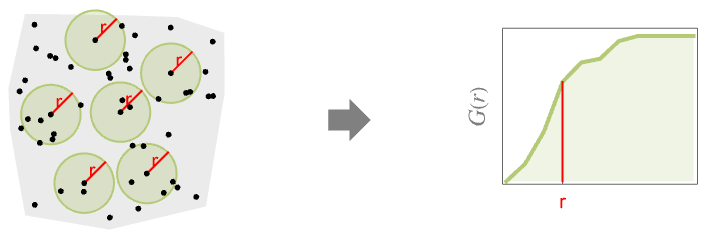
通常将 NearestNeighborG 与 EmptySpaceF 进行比较,估计在距参考点距离 r 内找到另一个点的可能性:
EmptySpaceF 即 CDF:
针对 HardcorePointProcess 生成的点数据,比较 NearestNeighborG 和 EmptySpaceF 给出的估计:
PoissonPointProcess 的空白空间和最近邻函数是一样的:
它们都相当于 ExponentialDistribution 的 CDF:
文本
Wolfram Research (2020),NearestNeighborG,Wolfram 语言函数,https://reference.wolfram.com/language/ref/NearestNeighborG.html.
CMS
Wolfram 语言. 2020. "NearestNeighborG." Wolfram 语言与系统参考资料中心. Wolfram Research. https://reference.wolfram.com/language/ref/NearestNeighborG.html.
APA
Wolfram 语言. (2020). NearestNeighborG. Wolfram 语言与系统参考资料中心. 追溯自 https://reference.wolfram.com/language/ref/NearestNeighborG.html 年