Predict
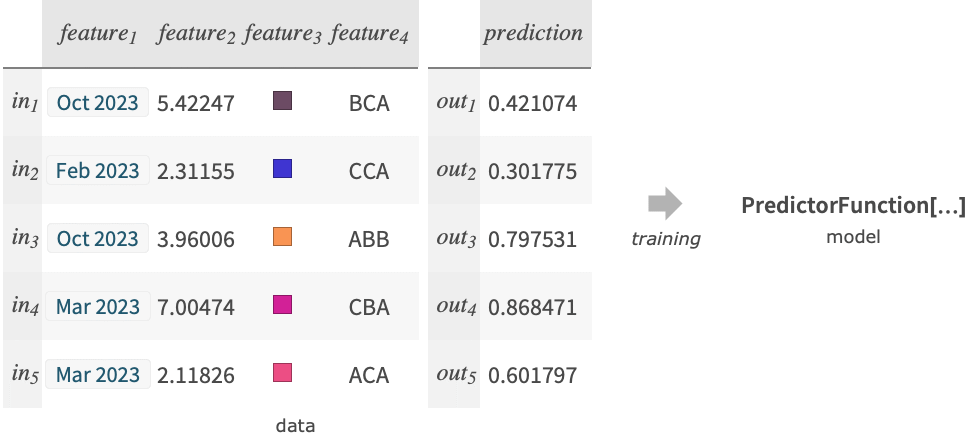
Predict[{in1out1,in2out2,…}]
例 iniから outiを予測しようとするPredictorFunctionを生成する.
Predict[data,input]
与えられた訓練例から input に関連付けられた出力を予測しようとする.
Predict[data,input,prop]
指定された特性 prop を予測と相対的に計算する.
詳細とオプション




- Predictは,数値,テキスト,サウンド,画像等を含むさまざまなタイプのデータとスカラー変数との間の関係をモデル化するために使われる.
- この種のモデリングは,回帰分析としても知られるもので,顧客の行動分析,医療成果の予測,信用リスク評価等によく使われる.
- 複雑な式は,数やクラスのようにより単純な特徴に自動的に変換される.
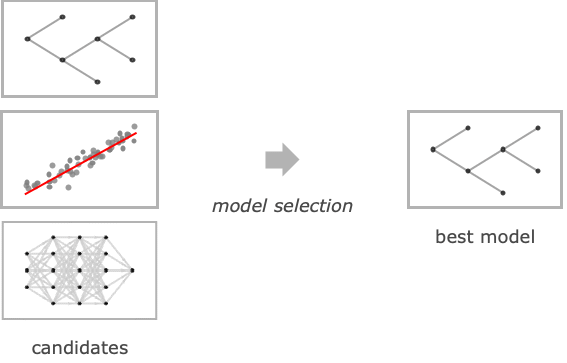
- 最終的なモデルタイプとハイパーパラメータ値は,訓練データについてのクロス確認を使って選択される.
- 以下は,使用可能な訓練 data の構造である.
-
{in1out1,in2out2,…} 入力と出力の間のRuleのリスト {in1,in2,…}{out1,out2,…} 入力と対応する出力の間のRule {list1,list2,…}n 出力としての各Listの n 番目の要素 {assoc1,assoc2,…}"key" 入力としての各Associationの"key"要素 Dataset[…]column 出力としてのDatasetの指定された column - これに加え,data の特殊形には以下が含まれる.
-
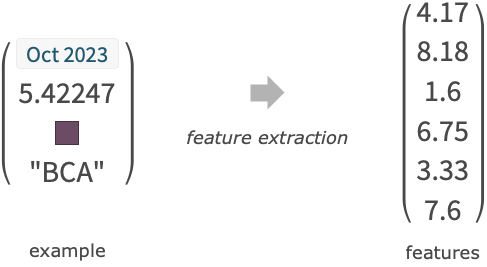
"name" 組込みの予測関数 FittedModel[…] PredictorFunction[…]に変換されたフィットモデル - 各例の入力 iniは,単一のデータ要素,リスト{feature1, …},あるいは連想<"feature1"value1,…>でよい.
- 各例の出力 outiは数値でなければならない.
- 予測特性 prop はPredictorFunctionと同じである.以下はその例である.
-
"Decision" 分布と効用関数に基づく最良の予測 "Distribution" 入力を条件とする値の分布 "SHAPValues" 各例のシャープレイ追加特徴の説明 "SHAPValues"n n 個のサンプルを使ったSHAPの説明 "Properties" 使用可能な全特性のリスト - "SHAPValues"は,さまざまな特徴を削除し次に合成した結果の予測を比較することで特徴の貢献度を評価する.オプションMissingValueSynthesisを使って欠測値を合成する方法が指定できる.SHAPの説明は訓練出力の平均からの偏差として与えられる.
- 次は,組込みの予測器関数の例である.
-
"NameAge" 名前を与えられた場合の人の年齢 - 次は,使用可能なオプションである.
-
AnomalyDetector None 予測器が使う異常検出器 AcceptanceThreshold Automatic 異常検出器の稀少確率閾値 FeatureExtractor Identity 学習対象となる特徴をどのように抽出するか FeatureNames Automatic 入力データに割り当てる特徴の名前 FeatureTypes Automatic 入力データに仮定する特徴タイプ IndeterminateThreshold 0 どの確率密度より下でIndeterminateを返すか Method Automatic 使用する回帰アルゴリズム MissingValueSynthesis Automatic 欠測値の合成方法 PerformanceGoal Automatic パフォーマンスのどの面について最適化するか RecalibrationFunction Automatic 予測された値をどのように後処理するか RandomSeeding 1234 どのような擬似乱数生成器のシードを内部的に使うべきか TargetDevice "CPU" そこで訓練を行うターゲットデバイス TimeGoal Automatic 分類器の訓練にどのくらい時間をかけるか TrainingProgressReporting Automatic 訓練中の進捗状況をどのようにレポートするか UtilityFunction Automatic 実測値/予測値の関数としての効用 ValidationSet Automatic 生成されたモデルを確かめるためのデータ - FeatureExtractor"Minimal"は内部の前処理を出来るだけ簡単にすべきであることを示す.
- 次は,Methodの可能な設定値である.
-

"DecisionTree" 決定木を使って予測する 
"GradientBoostedTrees" 勾配ブースティングで訓練した木の集合を使って予測する 
"LinearRegression" 特徴の線形結合から予測する 
"NearestNeighbors" 最近傍の例から予測する 
"NeuralNetwork" 人工の神経回路網を使って予測する 
"RandomForest" 決定木についてのBreimanおよびCutlerの集合体から予測する 
"GaussianProcess" ガウス過程の事前分布を関数に使って予測する - 次は,PerformanceGoalの可能な設定値である.
-
"DirectTraining" モデルを検索することなしに,直接データ集合全体について訓練する "Memory" 予測器の保存条件を最小にする "Quality" 予測器の確度を最大にする "Speed" 予測器の速度を最大にする "TrainingSpeed" 予測器の作成にかける時間を最小にする Automatic スピード,確度,メモリの自動トレードオフ {goal1,goal2,…} goal1,goal2等を自動的に組み合せる - TrainingProgressReportingの設定として以下を使うことができる.
-
"Panel" 動的に更新されるグラフィカルなパネルを表示する "Print" Printを使って定期的に情報をレポートする "ProgressIndicator" 簡単なProgressIndicatorを表示する "SimplePanel" 学習曲線なしでパネルを動的に更新する None 情報は何もレポートしない - 入手したPredictorFunction[…]にInformationを使うことができる.
例題
すべて開くすべて閉じる例 (2)
スコープ (23)
データ形式 (7)
データ型 (12)
数量 (1)
オプション (23)
AnomalyDetector (1)
FeatureExtractor (2)
FeatureExtractorを使ってカスタム関数でデータを前処理する予測関数を生成する:
FeatureNames (2)
名前付きの特徴がある訓練集合で予測器を訓練し,FeatureNamesを使ってその順序を設定する:
FeatureTypes (2)
IndeterminateThreshold (1)
Method (4)
MissingValueSynthesis (1)
欠測値の合成を設定して,既知の値が与えられた場合に各欠測変数を推定される最も可能性の高い値に置き換える(これはデフォルト動作である):
欠落している変数を既知の値を条件としてランダムサンプルで置き換える:
多くのランダムな代入を平均化することが通常は最良の戦略であり,代入によって引き起こされる不確実性を取得することができる:
訓練中に学習メソッドを指定して,データの分布についての学習方法を制御する:
"KernelDensityEstimation"分布を使って値に条件を付けることで欠落値のある例を予測する:
訓練で既存のLearnedDistributionを提供し,訓練中の欠落値の代入と後の評価でこれを使う:
個々の評価のために欠落値を合成するために既存のLearnedDistributionを指定する:
PerformanceGoal (1)
RecalibrationFunction (1)
TargetDevice (1)
ニューラルネットワークを使ってシステムのデフォルトGPUで予測器を訓練し,AbsoluteTimingを見る:
TimeGoal (2)
TrainingProgressReporting (1)
アプリケーション (6)
基本的な線形回帰 (1)
地域のいくつかの特徴を与え,ボストン近郊における不動産物件の中央値を予測する予測器を訓練する:
PredictorMeasurementsObjectを生成し,検定集合についての予測器のパフォーマンスを分析する:
気象分析 (1)
品質評価 (1)
解釈可能な機械学習 (1)
コンピュータビジョン (1)
顧客の行動分析 (1)
顧客の購買行動についてのデータを含むデータ集合をインポートする:
"GradientBoostedTrees"モデルを訓練して他の特徴から総支出額を予測するようにする:
このモデルを使って地域別の最も可能性が高い支出額を予測する:
特性と関係 (1)
正規化しない線形回帰予測器とLinearModelFitは,同等のモデルを訓練することができる:
FitとNonlinearModelFitは同等のこともある:
考えられる問題 (1)
RandomSeedingオプションは,常に結果の再生可能性を保証する訳ではない.
テキスト
Wolfram Research (2014), Predict, Wolfram言語関数, https://reference.wolfram.com/language/ref/Predict.html (2021年に更新).
CMS
Wolfram Language. 2014. "Predict." Wolfram Language & System Documentation Center. Wolfram Research. Last Modified 2021. https://reference.wolfram.com/language/ref/Predict.html.
APA
Wolfram Language. (2014). Predict. Wolfram Language & System Documentation Center. Retrieved from https://reference.wolfram.com/language/ref/Predict.html